Answers>Learn about blockchain security fundamentals>Common blockchain failure modes
Common blockchain failure modes
// Tags
blockchain failureblockchain attacks
TL;DR: Blockchain failure modes span three distinct layers: consensus-layer failures (validator bugs, network partitions, 51% attacks), application-layer failures (smart contract vulnerabilities, oracle manipulation, governance exploits), and infrastructure-layer failures (node crashes, provider outages, cloud incidents). Each layer has its own attack vectors, risk profiles, and mitigation strategies. Understanding these failure modes is essential for building resilient blockchain applications, because the consequences of failure in a system handling real financial value are far more severe than in traditional software.
The Simple Explanation
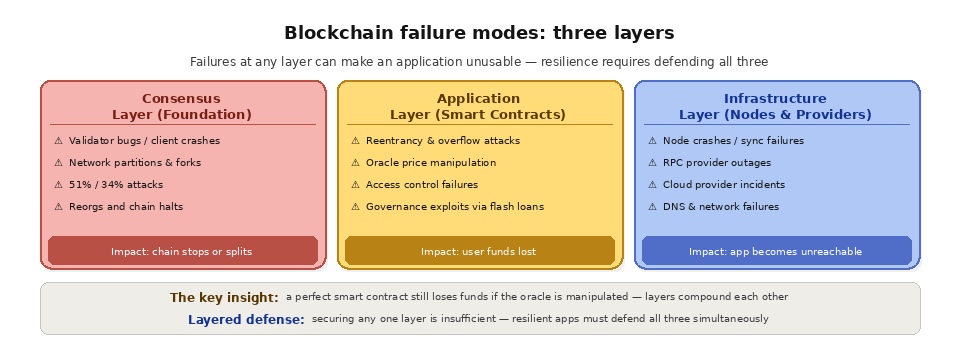
Blockchains are often described as trustless and immutable, but that does not mean they are infallible. Like any complex distributed system, blockchains can fail in multiple ways at multiple levels. The critical insight for developers is that blockchain failures are layered: a perfectly secure smart contract can still lose user funds if the oracle feeding it data is manipulated, and a perfectly written application can still break if the underlying node infrastructure goes down.
Think of it like a building. The foundation (consensus layer) could crack. The plumbing and wiring (application layer) could leak or short out. The property management company (infrastructure layer) could go bankrupt. Each failure mode requires a different kind of protection, and real-world resilience requires defending against all three simultaneously.
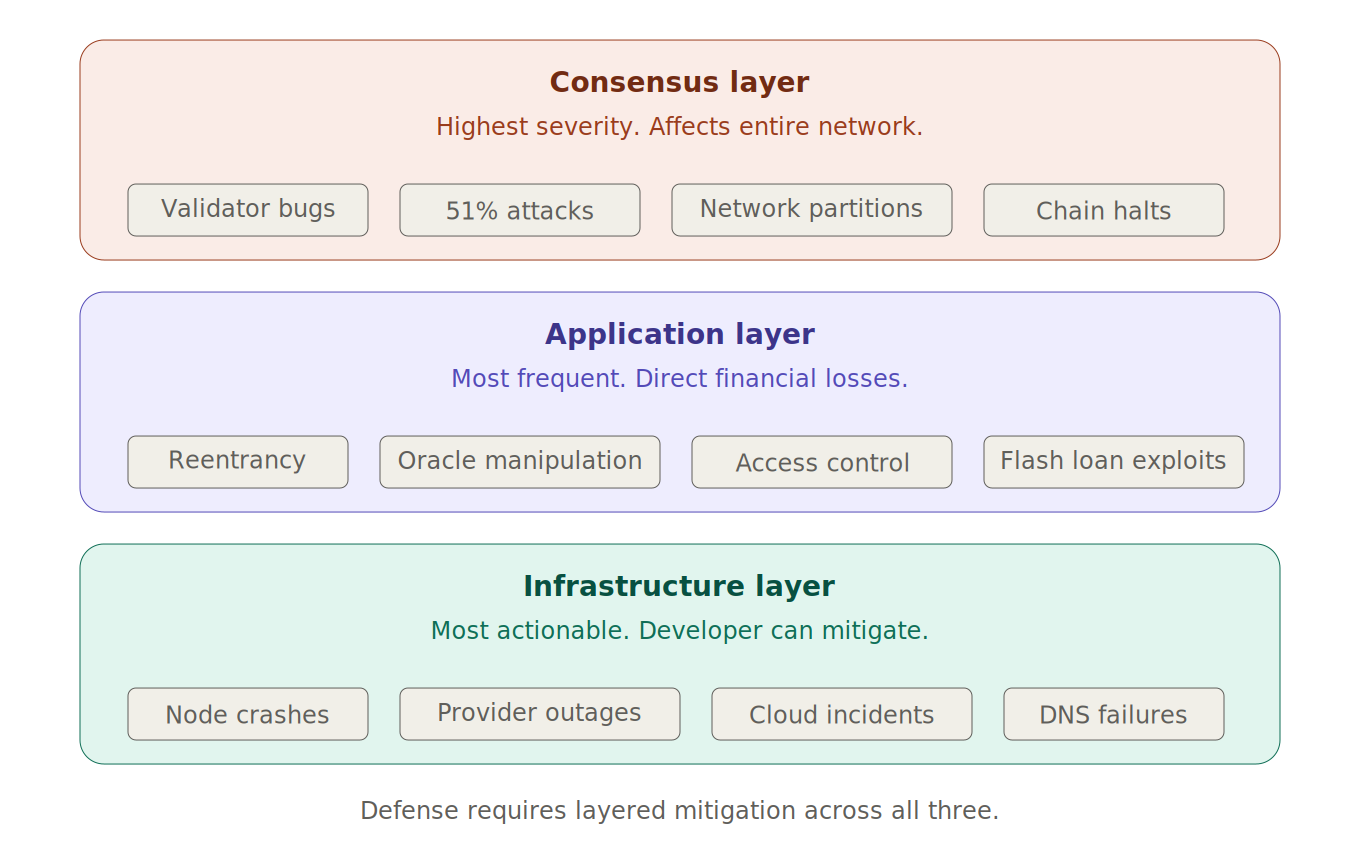
Consensus-Layer Failures
The consensus layer is the foundation of every blockchain. It is the mechanism by which validators agree on which transactions are valid and which blocks should be added to the chain. When consensus fails, the consequences are the most severe: the chain can halt, reorganize, or produce conflicting blocks.
Validator bugs are among the most common consensus-layer failure modes. Blockchain client software is complex, and bugs in block production, attestation logic, or state transition computation can cause validators to produce invalid blocks, crash during consensus rounds, or disagree with other validators about the correct state. The risk is amplified when a single client implementation dominates the network. If 70% of validators run the same client and that client has a bug, 70% of the network is affected simultaneously. This is why client diversity, running multiple implementations of the same protocol, is a recurring theme in blockchain security.
Network partitions occur when groups of validators lose the ability to communicate with each other, typically due to internet infrastructure issues, targeted DDoS attacks, or geographic routing failures. If a partition separates enough validators to prevent either side from reaching the consensus threshold (typically two-thirds of staked weight), block production halts. If the partition is partial (both sides can still reach threshold independently), the chain can temporarily fork, with each partition producing its own blocks. When the partition heals, a reorg resolves the fork, but transactions in the shorter fork are reversed.
51% attacks (or 34% attacks on BFT-based chains) allow an attacker with majority consensus power to rewrite recent chain history. The attacker produces a private chain that diverges from the public chain, accumulates more proof of work or validator attestations, and then broadcasts it to the network. Because the attacker's chain has more cumulative weight, the network adopts it as canonical, orphaning the public chain's recent blocks. This enables double-spending: the attacker sends funds on the public chain, waits for confirmation, then publishes their private chain that does not include the transaction, effectively getting the goods while keeping the funds.
Application-Layer Failures
The application layer encompasses smart contracts, DeFi protocols, oracles, and the onchain logic that manages billions of dollars in user funds. Application-layer failures are the most frequent and most costly source of blockchain losses.
Reentrancy attacks exploit a vulnerability where a smart contract makes an external call to another contract before updating its own state. The called contract can "re-enter" the original contract and execute the same function again before the state update occurs, potentially draining funds. The DAO hack in 2016, which led to the Ethereum/Ethereum Classic fork and resulted in approximately $60 million in losses, was a reentrancy attack. Despite being well-known for years, reentrancy vulnerabilities continue to appear in new contracts that fail to follow the checks-effects-interactions pattern.
Integer overflow and underflow vulnerabilities occur when arithmetic operations produce results outside the range of the data type, causing values to wrap around. A subtraction that should produce a negative number might instead produce an astronomically large positive number, allowing an attacker to claim more tokens than they are entitled to. Solidity 0.8.0 added built-in overflow checks that revert on overflow, but contracts compiled with older versions or those using unchecked arithmetic blocks remain vulnerable.
Access control failures happen when administrative functions lack proper authorization checks, allowing unauthorized users to call functions meant only for contract owners or specific roles. This includes unprotected upgrade functions (allowing anyone to replace the contract's logic), missing ownership checks on withdrawal functions, and improperly configured role-based access.
Oracle manipulation is a particularly insidious attack vector because it exploits the interface between onchain and offchain data. Smart contracts that rely on price oracles for lending, liquidation, or derivatives can be tricked into acting on manipulated prices. Flash loan attacks are the most common vehicle: an attacker borrows a large amount of tokens, uses them to manipulate the price on a DEX that the oracle references, triggers a profitable action on the target protocol at the manipulated price, and repays the flash loan, all in a single atomic transaction. The target protocol's smart contract functioned exactly as designed. The failure was in the oracle design, which did not account for short-term manipulation.
Governance exploits target the decentralized governance mechanisms of DAOs and DeFi protocols. An attacker acquires enough governance tokens (often through flash loans) to pass a malicious proposal that extracts funds from the treasury, modifies protocol parameters to create exploitable conditions, or changes access controls to give the attacker administrative power.
Infrastructure-Layer Failures
Infrastructure-layer failures do not compromise the blockchain itself but disrupt the ability of applications and users to interact with it. For end users and developers, an infrastructure failure can be indistinguishable from a chain-level failure because the practical result is the same: the application does not work.
Node crashes and sync failures take individual nodes offline or cause them to serve stale data. A node that has fallen behind the chain tip by several blocks returns outdated balances, misses recent transactions, and may reject valid transactions that depend on recent state changes. Applications that rely on a single node (without failover) go down completely when that node fails.
Provider outages affect all customers of a given infrastructure provider simultaneously. If a major RPC provider experiences an outage, every application using that provider's endpoints loses access to the blockchain. This is a centralization risk within a supposedly decentralized ecosystem: thousands of applications sharing the same infrastructure provider creates a single point of failure.
Cloud provider incidents affect blockchain infrastructure just like any other cloud-hosted service. When AWS, GCP, or another cloud provider experiences a regional outage, any blockchain nodes running in that region go offline. Because a disproportionate number of blockchain nodes run on a small number of cloud providers, cloud outages can have an outsized impact on network health and application availability.
DNS and networking failures can prevent applications from reaching their RPC endpoints even when the endpoints are functioning normally. DNS hijacking, BGP routing issues, and TLS certificate problems can all disrupt the connection between an application and its blockchain infrastructure.
Mitigation Strategies
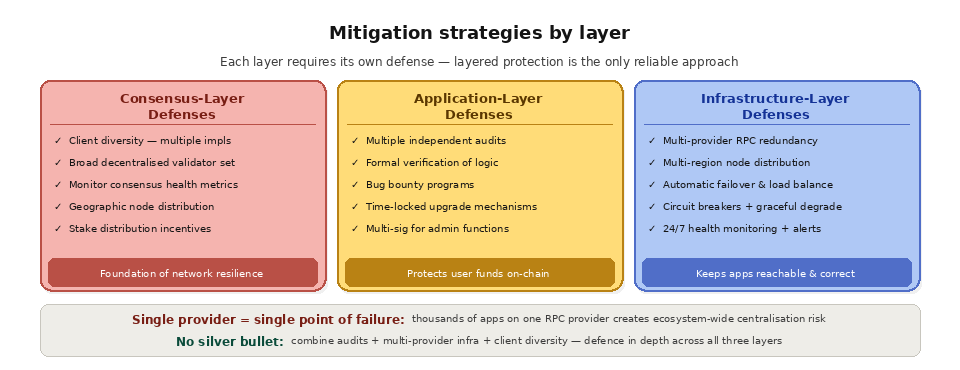
Defending against blockchain failure modes requires a layered approach that addresses all three levels.
At the consensus layer, client diversity is the single most impactful defense. Running multiple client implementations means a bug in one client does not affect the entire network. Stake distribution matters too: encouraging a broad, decentralized validator set reduces the risk of coordinated failures and 51% attacks. At the application layer, security audits, formal verification, and bug bounty programs are the primary defenses.
Smart contracts should be audited by multiple independent firms before deployment. Formal verification mathematically proves that contract code matches its specification, catching bugs that manual review might miss. Bug bounties incentivize white-hat hackers to find and responsibly disclose vulnerabilities. Time-locked upgrades give the community time to review proposed changes before they take effect, preventing malicious or buggy upgrades from being deployed instantly. Multi-signature requirements for administrative functions ensure that no single compromised key can execute privileged operations.
At the infrastructure layer, redundancy across providers, regions, and cloud platforms is the foundation of resilience. Applications should never depend on a single RPC provider, a single data center, or a single cloud provider. Circuit breakers prevent cascading failures by automatically disconnecting failing components before they take down upstream systems. Graceful degradation designs allow applications to continue providing core functionality (like displaying balances) even when some infrastructure components are unavailable.
How Quicknode Builds Resilience
Quicknode's infrastructure is designed to mitigate infrastructure-layer failures through geographic distribution across 14+ regions and 5+ cloud and bare-metal providers, client diversity where available, automatic failover that routes requests away from unhealthy nodes, and 24/7 monitoring by a dedicated blockchain operations team.
Quicknode Streams provides resilience for data pipelines through guaranteed delivery, finality-order processing, and automatic reorg handling. When consensus-layer events like reorgs occur, Streams detects and corrects affected data automatically. For application-layer monitoring, Streams enables developers to watch for specific contract events, unusual transaction patterns, and state changes that might indicate an exploit in progress.
For teams with the most stringent reliability requirements, Quicknode's Dedicated Clusters provide isolated infrastructure with guaranteed uptime SLAs, independent from shared traffic. This eliminates the "noisy neighbor" risk where another customer's traffic spike could degrade your performance, and provides the isolation needed for mission-critical blockchain applications.
What are the most common types of blockchain failures?
The failure modes covered above can be grouped by the layer they originate in, which also tells you who is responsible for defending against each one. The table below summarizes the most common failures, a representative example, and where mitigation lives.
Layer
Common failure
Example
Where mitigation lives
Consensus
51% attack or reorg
Majority rewrites recent history
Protocol and validator set
Consensus
Network partition or halt
Validators cannot reach threshold
Protocol and client diversity
Application
Reentrancy or oracle manipulation
Flash loan drains a lending pool
Smart contract and audits
Application
Access control or governance exploit
Unprotected admin function
Smart contract and multisig
Infrastructure
Node crash or provider outage
RPC endpoint returns stale data
Redundant infrastructure
How do you detect blockchain failures before they cause losses?
Detection is the difference between a contained incident and a catastrophic one. Continuous monitoring of blockchain infrastructure surfaces node lag, error spikes, and sync gaps in real time, while broader observability ties those signals to application behavior so you can see an exploit or outage developing before users feel it.
What is the difference between a chain halt and a chain reorg?
These two consensus-layer failures are often confused. A chain halt stops block production entirely because validators cannot reach the consensus threshold, so no new transactions confirm. A blockchain reorg keeps producing blocks but replaces recently accepted ones with a competing chain, which can reverse transactions that looked confirmed.
How does infrastructure redundancy reduce failure risk?
Most infrastructure-layer outages come down to a single point of failure. Understanding why infrastructure redundancy matters leads directly to designs with multiple providers and regions, and automatic failover that routes around an unhealthy node before requests start erroring.
Frequently Asked Questions
What are the three layers of blockchain failure?
Failures originate at the consensus layer (validator bugs, partitions, 51% attacks), the application layer (smart contract bugs, oracle manipulation, governance exploits), or the infrastructure layer (node crashes, provider and cloud outages). Resilient systems defend against all three.
What is the most common cause of blockchain losses?
Application-layer failures, especially smart contract vulnerabilities and oracle manipulation, are the most frequent and most costly. The underlying chain often works exactly as designed while flawed contract or oracle logic is exploited.
Can a single RPC provider outage take down my app?
Yes. If your application depends on one provider, one data center, or one cloud region, an outage there takes you offline. Spreading traffic across redundant providers and regions with automatic failover removes that single point of failure.
Is a 51% attack the same as a network partition?
No. A 51% attack is a deliberate effort by a majority of consensus power to rewrite history, while a network partition is an accidental loss of communication between validators. Both can cause reorgs, but their causes and defenses differ.
How do you protect against oracle manipulation?
Use oracles that aggregate prices across sources and time, avoid relying on a single DEX spot price, and add sanity checks and circuit breakers. These measures blunt flash loan attacks that briefly distort a price feed.