Answers>Learn about blockchain security fundamentals>What is a chain halt?
What is a chain halt?
// Tags
chain haltblockchain halt
TL;DR: A chain halt occurs when a blockchain stops producing new blocks entirely. Unlike congestion, where the network slows down but keeps running, a chain halt means zero new transactions are being confirmed and the network is effectively frozen. Chain halts are caused by consensus failures, critical client bugs, DDoS attacks on validators, resource exhaustion, or failed upgrades. They are among the most severe incidents a blockchain can experience because every application, wallet, and protocol built on that chain becomes unusable until the network resumes. Recovery requires coordinated action across the validator set, typically involving identifying the root cause, deploying a patch, and restarting consensus.
The Simple Explanation
A chain halt is the blockchain equivalent of a complete server outage. When a traditional web application's server goes down, no one can access the service. When a blockchain halts, no one can send transactions, claim yields, close positions, or interact with any smart contract on the network. The chain simply stops advancing.
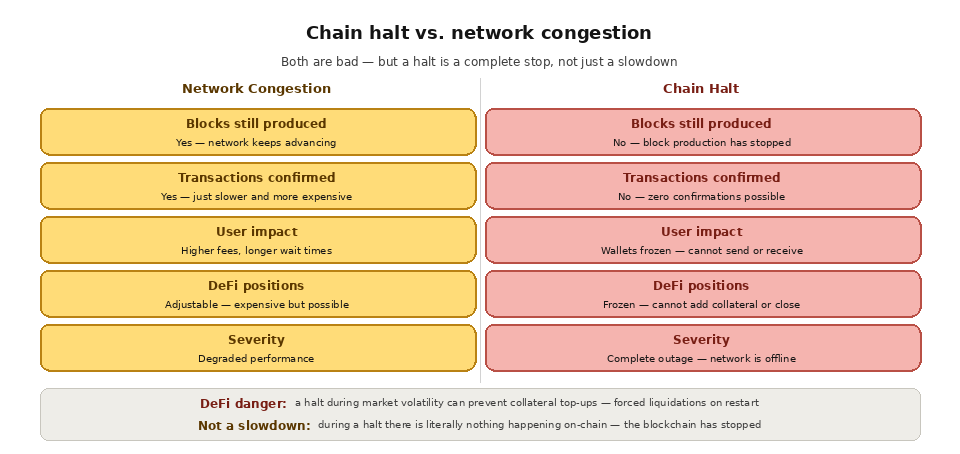
The distinction between congestion and a halt is important. During congestion, blocks are still being produced and transactions are still being confirmed, just more slowly and at higher cost. Users compete for limited block space, but the network is functional. During a chain halt, there are no blocks being produced at all. The network has stopped. Transactions sit in the mempool with no possibility of confirmation until the chain resumes.
For end users, a chain halt means wallets show balances but cannot send or receive funds. DeFi positions cannot be adjusted, which is especially dangerous during volatile market conditions when users might need to add collateral or close leveraged positions. NFT auctions freeze mid-bid. Bridges stop processing transfers. Every application built on the chain is effectively offline.
Common Causes of Chain Halts
Consensus failures are the most frequent cause of chain halts. A blockchain produces new blocks through its consensus mechanism, which requires a minimum threshold of validators to agree on the next block. On many Proof of Stake chains, this threshold is two-thirds of the staked validator weight. If enough validators go offline, crash, or become unable to communicate with each other, the network cannot reach consensus, and block production stops.
Critical client bugs can halt a chain if the bug causes validators to crash, produce invalid blocks, or disagree about the correct state. If a bug in the dominant client implementation causes most validators to produce conflicting blocks, the network can enter a state where no block receives enough attestations to be finalized. This scenario underscores the importance of client diversity: if every validator runs the same software, a single bug affects the entire network simultaneously.
Failed upgrades are another common trigger. Network upgrades require validators to update their software before a specific block or time. If the upgrade introduces a bug, or if the coordination is imperfect and some validators upgrade while others do not, the chain can split or stall. The risk increases with the complexity of the upgrade and the number of changes being deployed simultaneously.
DDoS attacks targeting validators can overwhelm their network connections or processing capacity, preventing them from participating in consensus. If enough validators are knocked offline by a coordinated attack, the chain halts until the attack subsides or validators deploy countermeasures.
Resource exhaustion occurs when transaction volume or smart contract complexity exceeds the network's processing capacity to the point where validators cannot keep up. Solana experienced this in September 2021 when an influx of bot activity overwhelmed validators' processing capabilities, eventually causing the network to halt for approximately 17 hours.
The Recovery Process
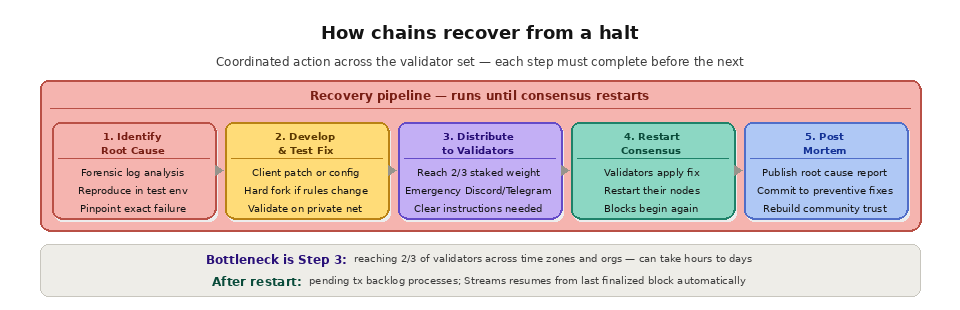
Recovering from a chain halt follows a general pattern, though the specifics vary by chain and by the cause of the halt.
First, the engineering team identifies the root cause. This often requires forensic analysis of validator logs, consensus state, and network conditions at the time of the halt. For bugs, reproducing the issue in a test environment is essential before a fix can be deployed.
Second, a fix is developed and tested. Depending on the severity and nature of the bug, this can take hours or days. The fix might be a client software patch, a configuration change, or in extreme cases, a hard fork that modifies the consensus rules.
Third, the fix is distributed to validators. This is the coordination challenge. Validators are independent operators spread across time zones and organizations. Reaching enough validators to restart consensus (typically two-thirds of staked weight) requires communication channels, clear instructions, and patience. Most chains maintain emergency communication channels (Discord, Telegram, or dedicated alert systems) for exactly this purpose.
Fourth, consensus restarts. Validators apply the fix, restart their nodes, and begin producing and attesting to blocks again. The chain resumes from the last finalized block, and the backlog of pending transactions begins processing.
Fifth, a post-mortem is conducted. The engineering team publishes a detailed analysis of what went wrong, why it happened, what was done to fix it, and what changes will be implemented to prevent recurrence. Post-mortems are essential for maintaining community trust and for improving the network's resilience.
What is the difference between a chain halt and network congestion?
These two failure modes are often confused, but they are very different in severity. Congestion means the network is overloaded yet still producing blocks, while a halt means block production has stopped entirely. The table below contrasts the two.
Aspect
Network congestion
Chain halt
Block production
Continues, just slower
Stops completely
Transactions
Confirmed at higher fees
None confirmed until recovery
User impact
Slow, expensive transactions
Funds frozen, apps offline
Typical cause
High demand for block space
Consensus or client failure
Resolution
Demand falls or fees adjust
Coordinated validator restart
If you are seeing slow transactions rather than a frozen chain, the issue is more likely blockchain congestion. Understanding why blockchains slow down helps you tell the two apart before escalating an incident.
What happens to my transactions during a chain halt?
Pending transactions sit unconfirmed in the mempool because no validator can include them in a block. They are not lost: once the chain resumes, the backlog is processed, though some may expire or need to be resubmitted with updated parameters. Because no new blocks are produced, no transaction reaches finality during the halt, so balances appear static even if a transaction looks pending.
When the network restarts, validators converge on the last canonical state, which can involve a short reorg as competing blocks are resolved. Applications should treat the immediate post-restart period cautiously and wait for finality before acting on freshly confirmed transactions.
How long do chain halts last?
Chain halts have ranged from under an hour to most of a day, depending on the cause and how quickly validators can coordinate a fix. The table below lists several widely reported halts. Durations are approximate and based on public post-mortems.
Network
When
Approximate duration
Reported cause
Solana
September 2021
About 17 hours
Bot-driven resource exhaustion
Solana
February 2024
About 5 hours
Bug in a legacy loader
BNB Smart Chain
October 2022
About 8 hours
Validator pause after a bridge exploit
Arbitrum
January 2024
About 1 to 2 hours
Sequencer outage
Halts driven by a clear, reproducible bug tend to resolve faster than those requiring deep forensic analysis. Networks with strong failure-mode planning and rehearsed restart procedures recover the quickest.
How can developers protect applications from chain halts?
You cannot prevent a chain halt, but you can design applications that degrade gracefully and recover cleanly. Building for high availability is the foundation. The table below summarizes the most effective defenses.
Practice
What it does
Benefit
Graceful degradation
Show cached state, queue writes
Users keep a working UI
Multi-chain support
Route activity to a live chain
Reduces single-chain dependence
Health monitoring
Track block height progression
Detect a halt within seconds
Provider redundancy
Fail over between endpoints
Survives node and provider issues
Automatic failover keeps the read path healthy when a node or provider degrades, while Quicknode Streams resyncs your data pipeline automatically once block production resumes.
Frequently Asked Questions
Is a chain halt the same as a blockchain going down?
Effectively, yes. A chain halt means the network has stopped producing blocks, so no transactions confirm and every application on that chain is unusable until validators restart consensus. The data is intact, but the network is frozen.
Can you lose money during a chain halt?
Funds on the chain are not destroyed, but you can suffer indirect losses, especially in DeFi. If you cannot add collateral or close a leveraged position during a halt, you may face liquidation or adverse pricing the moment the chain resumes and prices update.
Which blockchains have experienced chain halts?
Several high-throughput networks have halted at least once, including Solana, BNB Smart Chain, Polygon, and some Layer 2 rollups via sequencer outages. Halts are more common on newer or highly optimized chains that push performance limits.
How is a chain halt fixed?
Engineers identify the root cause, develop and test a fix, distribute it to validators, and coordinate a restart once enough staked weight is back online. The chain then resumes from the last finalized block and processes the backlog.
Does a chain halt cause a reorg?
It can. When validators restart, they must converge on a single canonical chain, which sometimes discards competing blocks produced near the halt. Waiting for finality after a restart protects your application from acting on data that gets reorged out.
How Quicknode Handles Chain Halts
Quicknode's infrastructure team monitors the health and block production status of every supported chain 24/7. When a chain halt occurs, Quicknode's systems detect the halt immediately and communicate status updates to affected customers. The monitoring infrastructure tracks block height progression, validator participation rates, and consensus health metrics, providing early warning of potential halts before they impact block production.
During a chain halt, Quicknode's RPC endpoints continue to serve historical data and respond to read requests against the last confirmed state. Write operations (transaction submissions) will naturally fail or queue until the chain resumes, but applications can still query balances, contract state, and historical data from before the halt. When the chain resumes, Quicknode Streams automatically picks up from the last processed block and delivers any new blocks produced during and after the recovery, ensuring your data pipeline stays synchronized with the canonical chain without manual intervention. The built-in reorg handling in Streams is especially valuable during chain restarts, which can involve temporary forks as validators converge on the correct chain state.