Answers>Learn about indexing & blockchain data>How to access historical blockchain data
How to access historical blockchain data
// Tags
historical blockchain dataarchive data
TL;DR: Accessing historical blockchain data requires either an archive node (which stores every state snapshot from genesis) or a data backfilling tool that retrieves and stores past blocks in a queryable database. Standard full nodes only retain the most recent 128 blocks of state data and prune everything older, so querying a wallet's balance from six months ago on a full node will fail. The two main approaches are archive node RPC access for point-in-time state queries and streaming backfills for building comprehensive historical databases.
The Simple Explanation
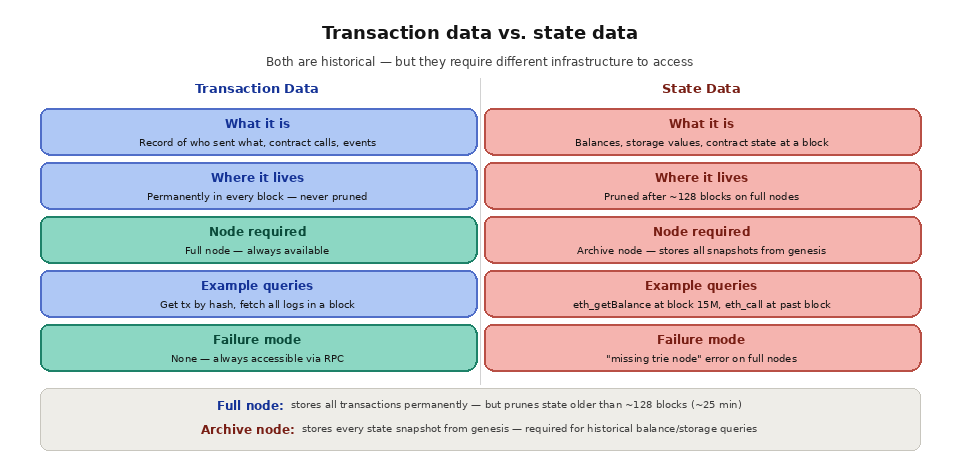
Blockchains record every transaction that has ever occurred, but that does not mean every piece of historical data is easily accessible. The distinction lies between transaction data and state data. Transaction data (the record of who sent what to whom, which contracts were called, which events were emitted) is permanent and available in every block. State data (the balances, storage values, and contract states at any given moment) is a different story.
Full nodes, which are the standard nodes most RPC providers operate, store the complete history of blocks and transactions but only maintain the current state and a rolling window of recent state snapshots (typically the last 128 blocks on Ethereum, roughly 25 minutes). They prune older state data to conserve storage. This means a full node can tell you what transactions happened in block 15,000,000, but it cannot tell you what a wallet's balance was at block 15,000,000 unless that block falls within the recent retention window.
When your application sends an RPC call like "eth_getBalance" with a historical block number to a full node, the node returns a "missing trie node" error because the state data for that block has been pruned. This is the most common surprise developers encounter when first working with historical data. The blockchain "remembers" everything in the sense that all transactions are recorded, but recovering the state at an arbitrary point in history requires special infrastructure.
What is the difference between a full node and an archive node?
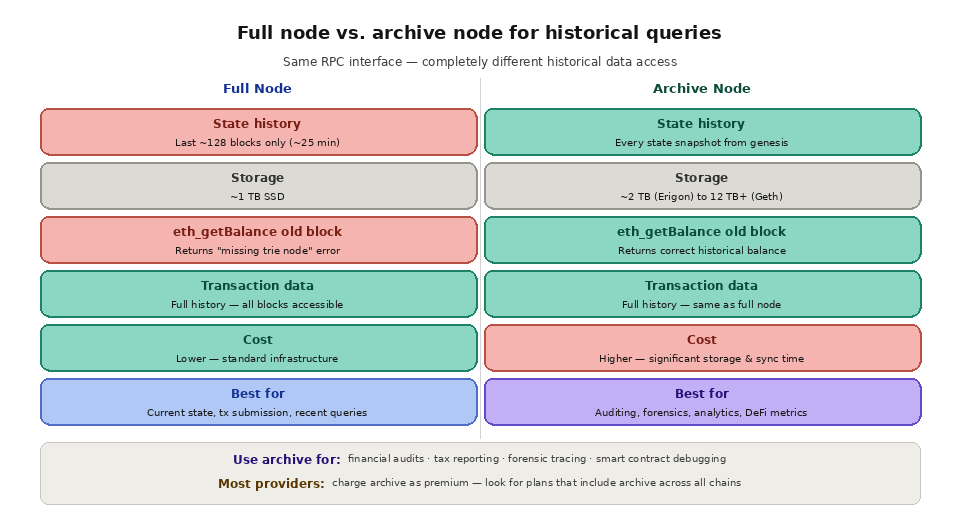
The fastest way to understand historical data access is to compare the two node types most providers run. A full node keeps the complete history of blocks and transactions but prunes old state, while an archive node keeps every historical state snapshot. If you only need recent data, a full node is cheaper and faster, but point-in-time historical state queries require an archive node. For a deeper breakdown, see our guide on full node vs archive node and the overview of what a blockchain node is.
Capability
Full node
Archive node
State retention
Last ~128 blocks (about 25 minutes on Ethereum)
Every state from genesis to latest
Storage footprint
Roughly 1TB on Ethereum
12TB or more on Ethereum
Historical state queries
Fails with a missing trie node error
Returns state at any block height
Cost to operate
Lower
Significantly higher
Best for
Current balances and recent activity
Audits, tax reporting, forensics, analytics
Archive Nodes for Point-in-Time Queries
Archive nodes solve the state pruning problem by retaining every state snapshot from the genesis block forward. An Ethereum archive node stores 12TB+ of data compared to roughly 1TB for a full node, making it significantly more expensive to run and maintain. But it enables a critical capability: querying the exact state of any account, contract, or storage slot at any historical block height.
This is essential for a range of use cases. Financial auditing requires reconstructing account balances at specific dates. Tax reporting needs to determine the value of holdings at year-end. Forensic analysis traces the flow of funds through historical state transitions. Smart contract debugging uses historical state to reproduce and analyze past bugs or exploits. DeFi protocol analytics calculate historical TVL, APY, and other metrics by querying pool states at past block heights.
Running your own archive node is resource-intensive. The initial sync takes weeks, storage costs are high, and the node requires ongoing maintenance, client updates, and monitoring. Most teams access archive data through infrastructure providers rather than running their own nodes. When evaluating providers, the key consideration is whether archive access is included in your plan or charged as a premium add-on, and whether the provider supports archive data across all the chains your application needs.
How far back can you query historical blockchain data?
With an archive node you can query the state of any account, contract, or storage slot all the way back to the genesis block. Transaction and event data is available from every block even on a standard full node, but historical balances and contract storage are only recoverable from an archive node. This distinction matters when you decide whether you need point-in-time state or a full record of past activity, a tradeoff we cover in real-time vs historical blockchain data. If your queries keep failing, it is usually because the request reached a full node, which is why understanding how RPC requests work helps you route them correctly.
Streaming Backfills for Historical Databases
Archive nodes answer point-in-time state queries, but many historical data use cases require something different: a complete, queryable database of past blocks, transactions, event logs, and traces. Building a blockchain analytics dashboard, a token transfer history API, or a comprehensive block explorer requires processing and storing historical block data in a structured database, not just querying an archive node on demand.
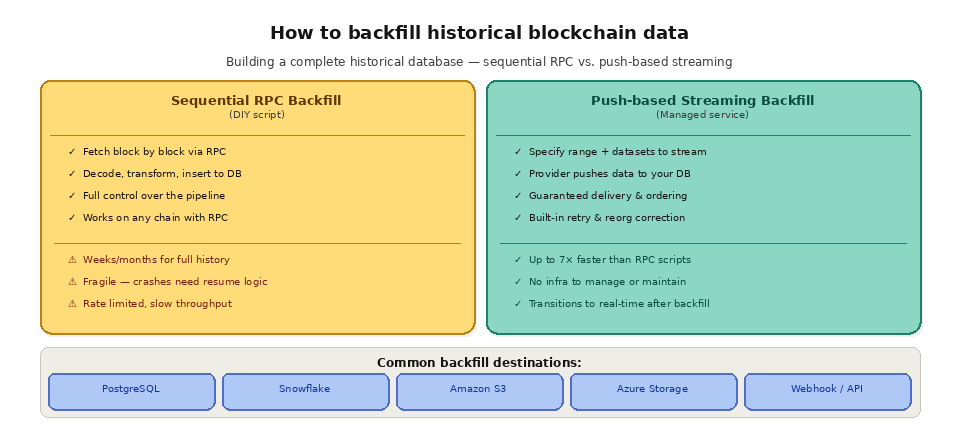
The traditional approach to building this database is writing a script that iterates through blocks one by one, fetches each block's data via RPC, decodes the transactions and logs, and inserts the results into your database. This works but is painfully slow and fragile at scale. Backfilling Ethereum's full history (20+ million blocks) via sequential RPC calls can take weeks or months. The script must handle rate limiting, connection failures, node timeouts, retries, and block ordering. If the script crashes halfway through, you need logic to resume from where it left off without creating gaps or duplicates in your data.
Push-based backfilling tools solve these operational headaches by handling the infrastructure complexity on the provider side. You specify a block range, select the datasets you need (blocks, transactions, receipts, traces, logs), optionally apply filters, and the system pushes the data to your destination with guaranteed delivery, correct ordering, and automatic retry on failure. Once the historical backfill completes, the same pipeline can transition to real-time streaming to keep your database current as new blocks are produced.
How long does a historical data backfill take?
Backfill time depends on the chain, the block range, and the datasets you request. A sequential script that fetches blocks one at a time over standard RPC can take weeks or months to cover 20 million blocks, and it has to handle retries, ordering, and resumption on its own. Managed push-based backfills parallelize the work and can complete up to seven times faster, with cost and completion estimates shown before you start. The throughput of your underlying RPC infrastructure is the main limiter for any do-it-yourself approach.
Other Methods for Historical Data
The Graph and other indexing protocols provide pre-indexed historical data for specific smart contracts through subgraphs. If someone has already deployed a subgraph for the protocol you need data from (like Uniswap, Aave, or Lido), you can query historical data through their GraphQL API without building your own pipeline. The limitation is that subgraphs are contract-specific and schema-specific, so you can only query what the subgraph author chose to index.
Third-party data providers like Dune Analytics, Flipside Crypto, and Nansen maintain comprehensive historical databases across major chains and expose them through SQL interfaces or APIs. These are convenient for analytics and research but introduce dependency on a third party's data freshness, accuracy, and availability. For production applications that need to own their data pipeline, building on top of raw blockchain data (via archive nodes or backfill streams) provides more control and reliability.
Chain-specific explorers and APIs (like Etherscan's API) offer another access path for historical data, but they typically enforce strict rate limits on free tiers and may not provide the granularity or completeness that production applications require.
Which method should you use to access historical blockchain data?
There is no single best method: the right choice depends on whether you need point-in-time state, a full queryable database, or pre-aggregated analytics. The table below summarizes the main options. If your goal is efficient repeated access rather than one-off lookups, compare RPC vs indexing and review what blockchain indexing is before committing, since querying blockchain data at scale is harder than it first appears.
Method
Best for
Main limitation
Archive node RPC
Point-in-time state at any block
Not a bulk database
Streaming backfill
Building a complete queryable database
Requires a destination to store data
Indexing protocols and subgraphs
Contract-specific historical data
Limited to what was indexed
Third-party data APIs
Analytics and research
Dependency on a vendor
Block explorer APIs
Quick lookups
Strict rate limits and limited granularity
How Quicknode Provides Historical Data Access
Quicknode includes archive node access across all plans, eliminating the need to manage or pay separately for archive infrastructure. Every Quicknode RPC endpoint can serve historical state queries at any block height, from the genesis block to the latest. Quicknode's QRoute technology automatically routes historical state requests to archive nodes and current-state requests to full nodes, delivering both through a single endpoint URL with no configuration required.
For building historical databases, Quicknode Streams provides one-click backfill templates that let you populate your database with complete chain history across 20+ networks. You select the chain, dataset type (blocks, transactions, receipts, traces, or all-in-one combinations), and destination (PostgreSQL, Snowflake, Amazon S3, Azure Storage, webhooks), and Streams pushes the data with guaranteed delivery, correct block ordering, and built-in retry logic. Cost and completion time estimates are shown before you start, giving you full transparency. Backfills sync up to seven times faster than traditional RPC-based scripts, and once complete, the same Stream can continue in real-time mode to keep your database current.
Historical blockchain data is any record of past on-chain activity, including blocks, transactions, event logs, traces, and the state (balances and contract storage) at a given block height. Transaction data is permanent on every node, but historical state requires an archive node or a stored backfill.
Why does eth_getBalance fail for old blocks?
A standard full node prunes state older than roughly the last 128 blocks, so a historical eth_getBalance call returns a missing trie node error. Querying an archive node, which retains every state snapshot, resolves the error.
Do I need an archive node to access historical data?
You need archive access for point-in-time state queries at arbitrary block heights. If you only need historical transactions and event logs, you can read them from full nodes or store them in your own database through a backfill.
What is a blockchain data backfill?
A backfill retrieves a range of past blocks and their datasets and loads them into a database or storage destination. Push-based backfills handle ordering, retries, and guaranteed delivery, then can switch to real-time streaming once they catch up.
How much does an Ethereum archive node store?
An Ethereum archive node stores roughly 12TB or more, compared to about 1TB for a full node. The extra storage holds every historical state snapshot, which is why archive infrastructure costs more to run.