Answers>Learn about indexing & blockchain data>Why querying blockchain data is hard
Why querying blockchain data is hard
// Tags
blockchain data challenges
TL;DR: Blockchains are optimized for security and immutability, not for data retrieval. There are no built-in search functions, no SQL queries, no indexes, and no way to filter or aggregate data across blocks using standard RPC methods. Querying even simple questions like "show all transfers from this wallet" requires scanning millions of blocks sequentially. Add chain reorganizations, varying finality models, encoded data formats, and massive data volumes, and it becomes clear why blockchain data access is a significant engineering challenge.
The Simple Explanation
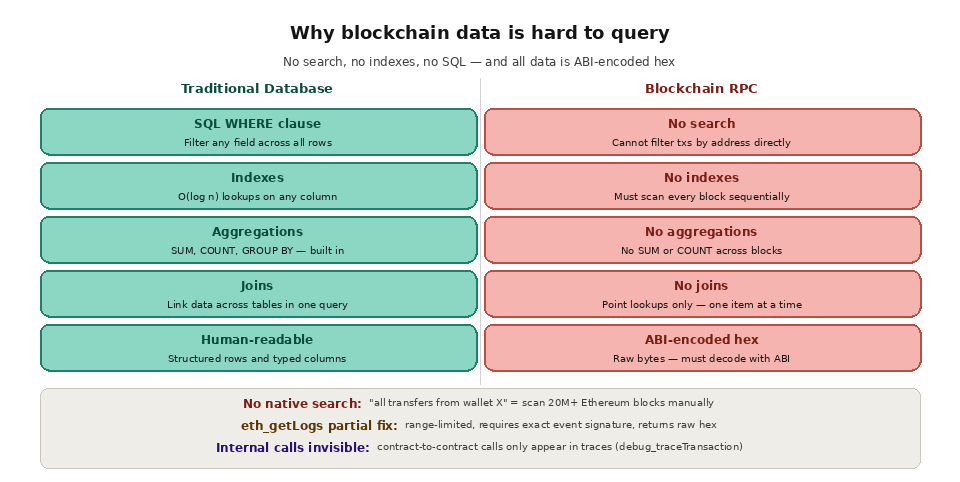
If you have ever used a traditional database, you know how easy it is to ask questions about your data. A single SQL query can return all orders from the last 30 days, grouped by customer, sorted by total value, filtered to only include amounts above $100. The database engine handles the heavy lifting because relational databases are designed from the ground up for flexible, efficient querying. They maintain indexes, support joins, enable aggregations, and optimize query execution plans automatically.
Blockchains are designed for the opposite purpose. Their primary job is to record transactions in a tamper-proof, decentralized ledger that thousands of independent nodes can verify and agree upon. Every design decision in a blockchain's architecture prioritizes consensus, security, and immutability. Data retrieval is, at best, an afterthought. The result is a data structure that is incredibly powerful for its intended purpose but frustrating to query for anything beyond simple point lookups.
No Native Search or Filtering
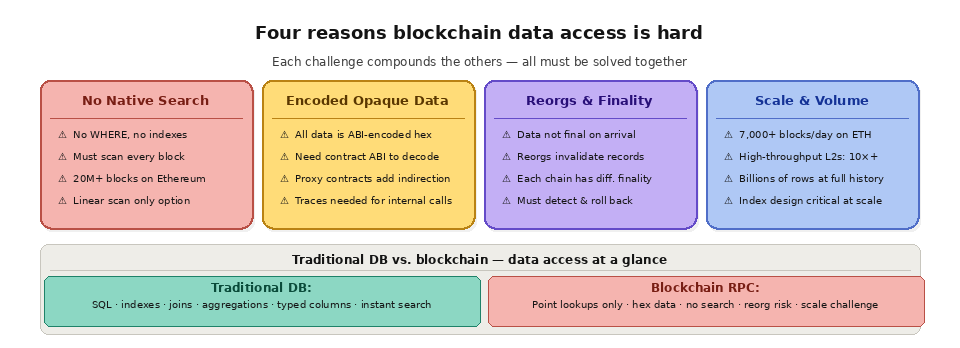
The most fundamental challenge is that blockchains have no search capability. There is no "find" command. There is no equivalent of SQL's WHERE clause. The RPC interface exposes a handful of low-level methods: fetch a block by number, fetch a transaction by hash, fetch an account's balance at a specific block. These are all point lookups where you must already know exactly what you are looking for.
If you want to find all transactions from a specific wallet address, you cannot ask the blockchain this question directly. You have to start at the genesis block, fetch every block in sequence, extract every transaction from each block, check the "from" and "to" fields of each transaction, and collect the matches. On Ethereum, this means iterating through over 20 million blocks, each containing anywhere from zero to several hundred transactions. On Solana, the numbers are even more staggering, with billions of slots and transactions in the chain's history. Without a pre-built index, this linear scan is the only way to answer the question.
The "eth_getLogs" method provides a partial solution by letting you query event logs within a block range filtered by contract address and topic. But it has strict block range limits (typically a few thousand blocks per request), requires you to know the exact event signature you are looking for, and returns raw ABI-encoded data that your application must decode. Building a complete picture of activity across multiple contracts, event types, and long time ranges requires hundreds or thousands of paginated log queries stitched together in your application code.
Encoded and Opaque Data Formats
Blockchain data is not human-readable by default. Transaction input data, event log parameters, and contract storage values are ABI-encoded into hexadecimal byte strings. To make sense of a transaction, your application needs the contract's ABI to decode the function call and its parameters. To interpret an event log, you need the ABI to map topic hashes back to event names and decode the data fields into typed values.
Complicating matters further, not every contract publishes its ABI. Unverified contracts on block explorers provide no decoding information, leaving their transactions and events opaque to external observers. Even with a verified ABI, proxy contracts (which delegate calls to implementation contracts) require your application to resolve the proxy relationship before it can decode the underlying function calls. These layers of indirection make automated, broad-spectrum blockchain data processing significantly more complex than working with a well-documented REST API.
Internal transactions add another layer of opacity. When one smart contract calls another, that internal call does not appear in the block's transaction list. It only appears in execution traces (accessed via debug_traceTransaction or trace_block methods), which are computationally expensive to generate and not available on all node types. A simple token swap on a DEX might involve a dozen internal contract calls, each transferring tokens, updating state, and emitting events. Capturing the complete picture of what happened requires trace data, which dramatically increases the data volume and processing complexity.
Chain Reorganizations and Finality
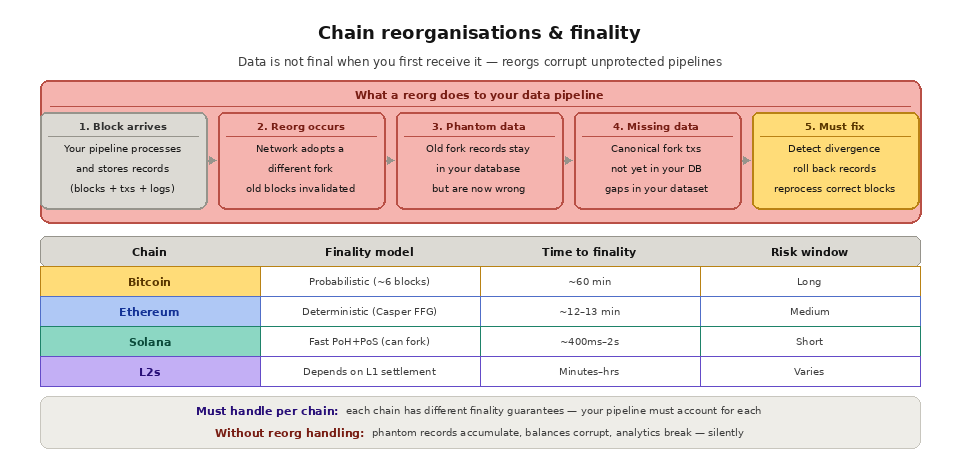
Blockchain data is not always final when you first receive it. Chain reorganizations (reorgs) occur when the network temporarily follows one fork of the chain and then switches to a different fork that becomes canonical. When a reorg happens, blocks that your application already processed become invalid. Transactions that appeared confirmed may no longer exist in the canonical chain, or they may appear in a different block at a different position.
For data pipelines and indexers, reorgs are a nightmare. Any records derived from reorganized blocks must be detected, rolled back, and replaced with data from the correct blocks. If your system does not handle reorgs, your database will accumulate phantom records (data from abandoned forks) and miss legitimate records (data from the canonical fork), leading to incorrect balances, duplicated transfers, and corrupted analytics.
Different chains have different finality characteristics, which compounds the problem. Bitcoin transactions are probabilistically final after approximately six confirmations (about 60 minutes). Ethereum achieves finality after two epochs (roughly 12-13 minutes). L2 chains like Arbitrum and Base have their own finality mechanisms that depend on when data is posted to Ethereum L1. Solana achieves fast finality but can still experience slot skipping and fork resolution. Your data pipeline must account for the specific finality model of every chain it processes.
Scale and Performance
The sheer volume of blockchain data is staggering and growing rapidly. Ethereum produces approximately 7,000 blocks per day, each containing hundreds of transactions and thousands of event logs. High-throughput chains like Solana, Base, and Arbitrum produce orders of magnitude more data. Ingesting, decoding, and storing all of this data in real time, while also maintaining a complete historical index, requires substantial computational and storage resources.
Performance degrades at scale in subtle ways. Database tables with billions of rows need careful index design, partitioning strategies, and query optimization to maintain acceptable response times. Concurrent writes from real-time ingestion compete with reads from user-facing queries. Storage costs compound as you add more chains, more datasets (traces, logs, state diffs), and more historical depth. What starts as a manageable data pipeline at 100 blocks per day becomes an infrastructure challenge at 100,000 blocks per day across 10 chains.
What are the main ways to query blockchain data?
There is no single tool for reading blockchain data. Teams pick from several approaches depending on whether they need a quick point lookup, a real-time feed, or rich historical analytics. The table below summarizes the common methods.
Approach
How it works
Best for
Direct RPC calls
Fetch a block, transaction, or balance by key
Point lookups and live state
Event logs (eth_getLogs)
Filter logs by address and topic in a block range
Tracking specific contract events
Indexers
Decode and store onchain data in a queryable database
Search, joins, and aggregation
Streaming pipelines
Push new and historical data to your own store
Continuous ingestion at scale
SQL and analytics platforms
Query pre-indexed tables with standard SQL
Dashboards and ad hoc analysis
Most production stacks combine several of these. They use RPC requests for live reads and a separate indexing or streaming layer for everything that needs search and history. To understand the lowest layer, see what an RPC endpoint actually does.
Why can't you use SQL directly on a blockchain?
A blockchain stores data as a sequence of cryptographically linked blocks, not as indexed tables, so there is no query planner, no WHERE clause, and no way to ask for "all swaps over $1,000 last week" in one call. Reaching that level of access means first extracting and decoding the raw data, then loading it into a system that does support structured queries. That extract, decode, and load step is exactly what blockchain indexing performs.
Should you use an RPC node or an indexer to query data?
RPC nodes and indexers solve different problems. An RPC node is perfect for direct lookups and submitting transactions, while an indexer is built for the search, filtering, and aggregation that raw nodes cannot do. The comparison below shows where each one fits.
Factor
RPC node
Indexer
Query style
Point lookups by key
Flexible search and filters
Aggregation
Not supported
Built in
Historical depth
Needs an archive node
Stored once, queried fast
Setup effort
Low, call an endpoint
Higher, build or buy a pipeline
Best use
Live state and transactions
Analytics and complex queries
For a deeper breakdown of when each one wins, see RPC vs indexing.
How do you query historical blockchain data?
Recent state can be read from any full node, but older state and full transaction history usually require an archive node or a backfill pipeline. The distinction between current and past data shapes your whole architecture, which is covered in real-time vs historical blockchain data and full node vs archive node. For one-off deep lookups, an archive endpoint works; for repeated analytics, indexing the history once is far more efficient.
Frequently Asked Questions
Can you query a blockchain like a normal database?
Not directly. Standard RPC methods only support point lookups by block number, transaction hash, or address. To run database-style queries with filtering and aggregation, you have to index the data into a system that supports them first.
What is the fastest way to get all transactions for a wallet?
Use an indexer or a pre-built data API. Scanning the chain block by block with raw RPC is too slow for this, while an indexed dataset can return a wallet's full history in a single query.
Why does decoded blockchain data require an ABI?
Transaction inputs and event logs are stored as ABI-encoded hex. The contract ABI is the schema that maps those bytes back to function names, event names, and typed values, so without it the data stays opaque.
How do reorgs affect blockchain queries?
A reorg can invalidate data you already read, so query results near the chain tip are not final. Robust pipelines wait for finality or send correction updates when the canonical chain changes.
Do you need to run your own node to query blockchain data?
No. Managed RPC providers, streaming services, and analytics platforms let you read and query blockchain data without operating any nodes or indexers yourself.
How Quicknode Simplifies Blockchain Data Access
Quicknode's product suite is designed to address each of these challenges directly. The Core API provides fast, reliable RPC access for point lookups and transaction submission, with enhanced API methods that aggregate common multi-step queries into single calls. Archive access is included across all plans, so historical state queries work without separate infrastructure or additional cost.
Quicknode Streams eliminates the data ingestion challenge entirely. Instead of building and maintaining custom scripts that poll RPC endpoints, handle pagination, manage retries, and detect reorgs, you configure a Stream that pushes exactly the blockchain data you need to your database or warehouse. Streams delivers data in finality order with exactly-once guarantees, handles chain reorganizations automatically by sending correction payloads, and supports both real-time streaming and historical backfills through the same pipeline. JavaScript-based filters run on Quicknode's infrastructure to decode, transform, and shape data before delivery, so your destination receives clean, structured records ready for querying.
For teams that want indexed blockchain data without building any pipeline at all, Quicknode's Marketplace includes partner integrations with indexing protocols and data services that provide pre-built, queryable datasets for common use cases.