Answers>Learn about indexing & blockchain data>What is blockchain indexing?
What is blockchain indexing?
// Tags
blockchain indexingblockchain indexer
TL;DR: Blockchain indexing is the process of extracting raw data from a blockchain, transforming it into a structured format, and storing it in a database optimized for fast queries. Blockchains are designed for security and immutability, not for searching. Without indexing, answering even simple questions like "show me all transfers from this wallet" requires scanning every block from genesis, which is impractical at scale. Indexers solve this by creating queryable databases that make onchain data accessible to applications in real time.
The Simple Explanation
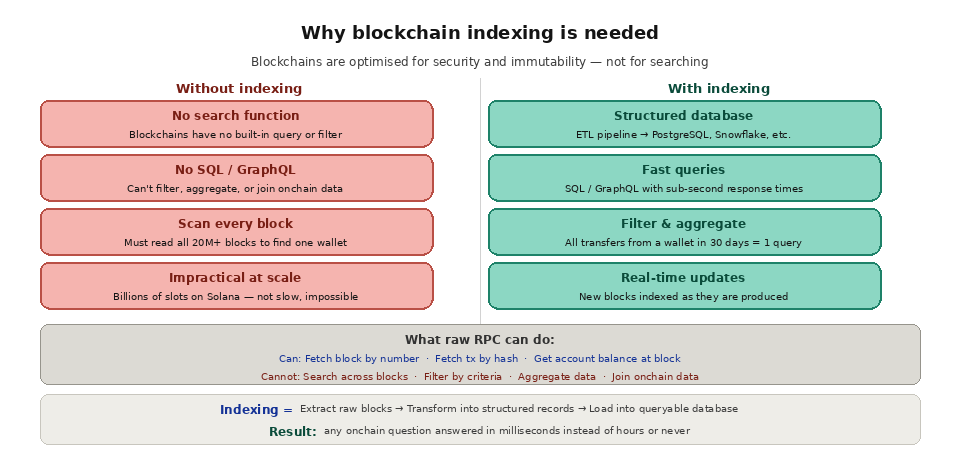
Blockchains are append-only ledgers. They are excellent at recording transactions in a tamper-proof sequence, but they are terrible at answering questions about those transactions. There is no built-in "search" function. There are no SQL queries. There is no way to say "find all ERC-20 transfers involving this address in the last 30 days" using standard RPC methods alone.
The raw tools available through RPC endpoints are primitive by design. You can fetch a specific block by number. You can fetch a specific transaction by hash. You can get an account balance at a specific block. But you cannot search across blocks, filter by criteria, aggregate data, or join information from different parts of the chain. To find all transactions from a specific wallet, you would need to fetch every block ever produced, extract every transaction from each block, check whether the sender or recipient matches your target address, and collect the matches. On Ethereum, that means scanning over 20 million blocks. On Solana, it means scanning billions of slots. Without indexing, this is not slow. It is impossible in any reasonable timeframe.
Blockchain indexing solves this by running a process that continuously reads new blocks from a node, decodes the raw data (transactions, event logs, state changes, traces), transforms it into structured records, and writes those records to a database with proper indexes. Once the data is in a database, your application can query it using familiar tools like SQL or GraphQL with sub-second response times.
How Indexing Works
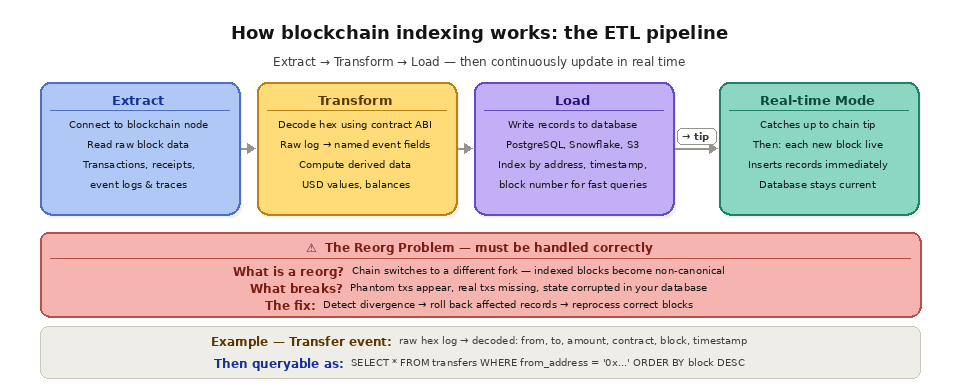
The indexing pipeline follows an Extract, Transform, Load (ETL) pattern. In the extract phase, the indexer connects to a blockchain node and reads raw block data. This includes block headers, transactions, transaction receipts (which contain event logs), and optionally trace data (which captures internal contract-to-contract calls). The indexer processes blocks sequentially, starting from a configured starting block and advancing through the chain's history.
In the transform phase, the indexer decodes the raw data into meaningful structures. Raw event logs, for example, are encoded as hex strings with topic hashes and data fields. The indexer uses the smart contract's ABI (Application Binary Interface) to decode these into human-readable events with named parameters and proper data types. A raw Transfer event log becomes a structured record with a "from" address, a "to" address, a token amount, and a contract address. The transform phase can also compute derived data, like calculating USD values at the time of transfer, aggregating volume by token, or tracking running balances.
In the load phase, the structured records are written to a database, whether PostgreSQL, MongoDB, Snowflake, Elasticsearch, or another storage system. The database creates indexes on the fields that applications will query (like wallet addresses, token contracts, timestamps, and block numbers), enabling fast lookups and complex queries across the entire dataset.
Once the indexer has caught up with the chain's tip, it switches to real-time mode, processing each new block as it is produced and inserting the resulting records immediately. This keeps the database current with the live state of the chain.
The Reorg Problem
One of the most challenging aspects of blockchain indexing is handling chain reorganizations. A reorg occurs when the blockchain's canonical chain changes, usually because competing blocks were produced at the same height and the network eventually converges on a different fork than the one your indexer initially processed. When this happens, the blocks your indexer already processed are no longer canonical, and any records derived from those blocks are incorrect.
A robust indexer must detect reorgs, roll back the affected records, and reprocess the correct blocks. Failing to handle reorgs leads to phantom transactions appearing in your database (transactions that were in the old fork but not the new one), missing transactions (transactions in the new fork that the old fork did not include), and incorrect state. For financial applications, this kind of data corruption is unacceptable.
Reorg handling adds significant complexity to the indexing pipeline. The indexer needs to track which blocks have been processed, compare the chain it sees against what it has already stored, detect divergences, and execute rollbacks cleanly. This is one of the primary reasons teams choose managed indexing solutions over building custom indexers from scratch.
Indexing Approaches
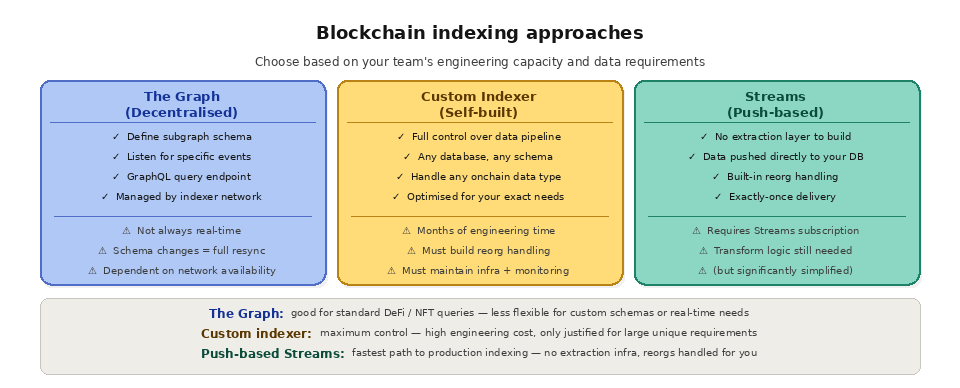
The Graph is the most widely adopted decentralized indexing protocol. Developers create "subgraphs," which are configuration files that define which smart contracts to monitor, which events to listen for, and how to map event data into a queryable schema. Independent node operators called Indexers run the processing infrastructure and serve queries via GraphQL endpoints. The Graph works well for standard use cases like querying DeFi protocol data, NFT ownership history, and DAO governance activity. Its limitations include latency (subgraph updates are not always real-time), schema inflexibility (changing your schema often requires redeploying and resyncing), and dependency on the decentralized network's availability.
Custom indexers give teams full control over their data pipeline but require significant engineering investment. Building a production-grade custom indexer means writing block ingestion logic, event decoding, database schema design, reorg handling, error recovery, monitoring, and scaling infrastructure. For large-scale applications with unique data requirements, this investment can be worthwhile, but for most teams it represents months of engineering time that could be spent on their core product.
Push-based streaming represents a newer approach that simplifies indexing by delivering filtered blockchain data directly to your storage system, eliminating the need to build and maintain the extraction layer yourself. Instead of your indexer pulling data from a node, a streaming service pushes exactly the data you need to your database, webhook, or data warehouse.
How Quicknode Powers Blockchain Indexing
Quicknode Streams is purpose-built for blockchain data indexing. Streams provides a push-based data pipeline that delivers raw or filtered blockchain data directly to your preferred destination, including PostgreSQL, Snowflake, Amazon S3, Azure Storage, and webhooks. Instead of building and maintaining RPC polling infrastructure to extract data from the chain, you configure a Stream with your desired network, dataset (blocks, transactions, receipts, traces), and optional JavaScript filters, and Quicknode handles the rest.
Streams delivers data in finality order with exactly-once delivery guarantees, which means your database stays consistent with the canonical chain without your code needing to manage block ordering or deduplication. Built-in reorg handling automatically detects chain reorganizations and sends correction payloads, so your indexed data always reflects the true state of the chain. For historical data, Streams' backfill feature lets you populate your database with any range of past blocks, syncing up to seven times faster than traditional RPC-based indexing pipelines, with the same filtering and delivery guarantees as real-time streaming.
Quicknode also publishes a step-by-step guide to building a blockchain indexer with Streams, demonstrating how to create a complete ERC-20 transfer indexer backed by PostgreSQL with a REST API, from configuration to querying. For teams that need even more sophisticated data processing, Streams integrates with Quicknode Functions to enable serverless transformations, enrichment, and automation on top of the streaming data pipeline.
What is the difference between indexing and raw RPC?
Raw RPC and indexing answer different kinds of questions. RPC is built for point lookups and writes: fetch this block, read this balance, send this transaction. Indexing is built for search and analytics: every transfer for a wallet, total volume by token, ownership history for a collection. The table below contrasts the two so you can pick the right tool for each job.
What kinds of queries does indexing make possible?
Once data is indexed into a structured database, questions that are impossible over raw RPC become trivial. You can list every transaction for an address, trace an NFT's full ownership history, aggregate trading volume per token per day, rank wallets by holdings, or join events across multiple contracts. These are exactly the queries that power dashboards, explorers, and analytics products. For why these queries are so hard without indexing, see querying blockchain data.
How do indexing and streaming work together?
Streaming and indexing are complementary layers. Streaming is the delivery mechanism that pushes new blocks and events to your infrastructure as they happen, while indexing is what organizes that incoming data into a queryable store. A common modern architecture uses a streaming pipeline to feed records into an indexed database, removing the brittle polling layer entirely. See what is blockchain data streaming and polling vs streaming for how data gets to the indexer in the first place.
How do indexers backfill historical data?
Backfilling is the process of populating your database with past blocks before switching to live data. A good pipeline starts at a chosen historical block, processes forward through the chain, and then transitions seamlessly to real-time once it reaches the tip, so historical and live records share one schema. Done well, backfilling is far faster than re-scanning the chain over raw RPC. See how to access historical blockchain data and real-time vs historical blockchain data for the trade-offs involved.
Frequently Asked Questions
Why can't I just use RPC instead of indexing?
RPC is excellent for fetching a specific block, transaction, or balance, but it offers no way to search, filter, or aggregate across the chain. Answering a question like "all transfers from this wallet" over RPC means scanning millions of blocks one by one, which is impractical. Indexing pre-processes that data into a database so the same question returns in a single query.
What is a subgraph?
A subgraph is a configuration used by The Graph that defines which contracts and events to index and how to map them into a queryable GraphQL schema. It is one popular way to build an index, well suited to standard DeFi, NFT, and governance data, though it can trade off real-time latency and schema flexibility compared to custom or streaming-based pipelines.
How do indexers handle chain reorganizations?
A robust indexer detects when the canonical chain changes, rolls back records derived from the orphaned blocks, and reprocesses the correct ones. Without this, your database accumulates phantom or missing transactions. Managed pipelines handle reorgs automatically by sending correction payloads. For background, see what is a blockchain reorg.
Should I build my own indexer or use a managed service?
Building a custom indexer gives full control but requires writing ingestion, decoding, schema design, reorg handling, monitoring, and scaling, which is often months of work. A managed pipeline handles extraction, ordering, reorgs, and delivery for you, so most teams reach production faster by configuring a service and focusing engineering effort on their core product.
What databases can indexed blockchain data be stored in?
Indexed data commonly lands in PostgreSQL, MongoDB, Snowflake, Elasticsearch, or object storage such as Amazon S3, depending on whether you need transactional queries, full-text search, or analytics at scale. A streaming pipeline can deliver records directly into these destinations. For end-to-end tutorials, the Builders Guide walks through common indexing patterns.