Answers>Learn about Web3 infrastructure architecture>Build vs buy blockchain infrastructure
Build vs buy blockchain infrastructure
// Tags
build vs buyself-host vs provider
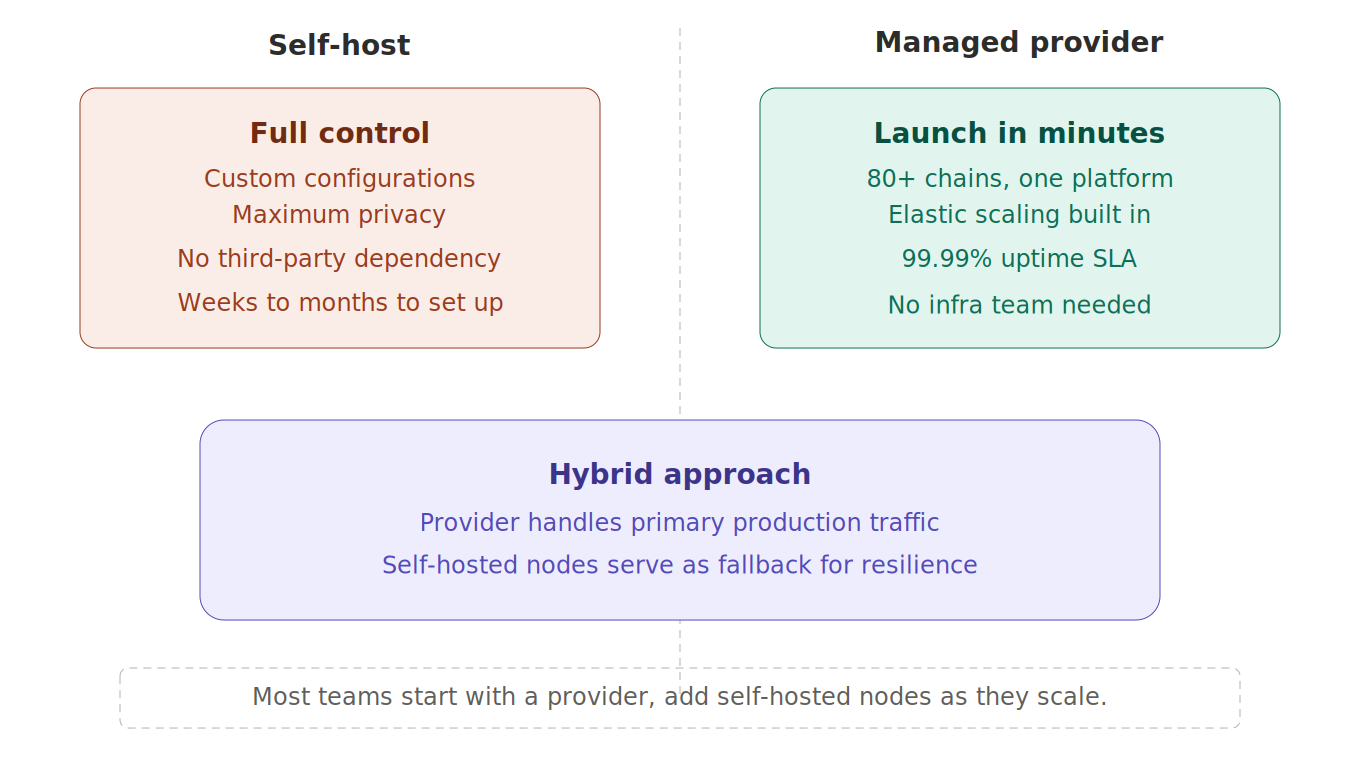
TL;DR: Choosing between building and buying blockchain infrastructure is one of the most consequential early decisions for any Web3 team. Self-hosting means running your own blockchain nodes, managing servers, handling client updates, and maintaining uptime, delivering full control and sovereignty but demanding significant DevOps expertise, weeks of initial setup, and ongoing operational investment. Using a managed provider lets teams launch in minutes with elastic scaling, built-in multi-chain support, and minimal operational overhead. The right choice depends on your team's capabilities, regulatory requirements, performance needs, and stage of development. Many mature organizations adopt a hybrid approach where a managed provider handles primary production traffic while self-hosted nodes serve as fallback infrastructure for resilience.
The Simple Explanation
Building your own blockchain infrastructure is like building your own data center versus renting server space from AWS. Both give you compute and storage, but the operational burden is vastly different. Running your own nodes means procuring hardware (or provisioning cloud instances), installing and configuring blockchain client software, syncing the chain from genesis (which can take days or weeks), monitoring uptime around the clock, applying client updates and security patches, managing disk storage as the chain grows, handling hard forks and protocol upgrades, and debugging sync failures when they inevitably occur.
Using a managed provider means signing up, creating an endpoint, and making your first RPC call within minutes. The provider handles all the operational complexity behind the scenes. You get a URL that connects your application to a professionally managed node, and the provider worries about uptime, scaling, client updates, and failover.
The tradeoff is control versus convenience. Self-hosting gives you maximum control over your infrastructure: you decide which client to run, how to configure it, where to host it, and what data to retain. A managed provider abstracts those decisions away, which is a benefit when you want to move fast and a limitation when you need customization that the provider does not offer.
When to Self-Host
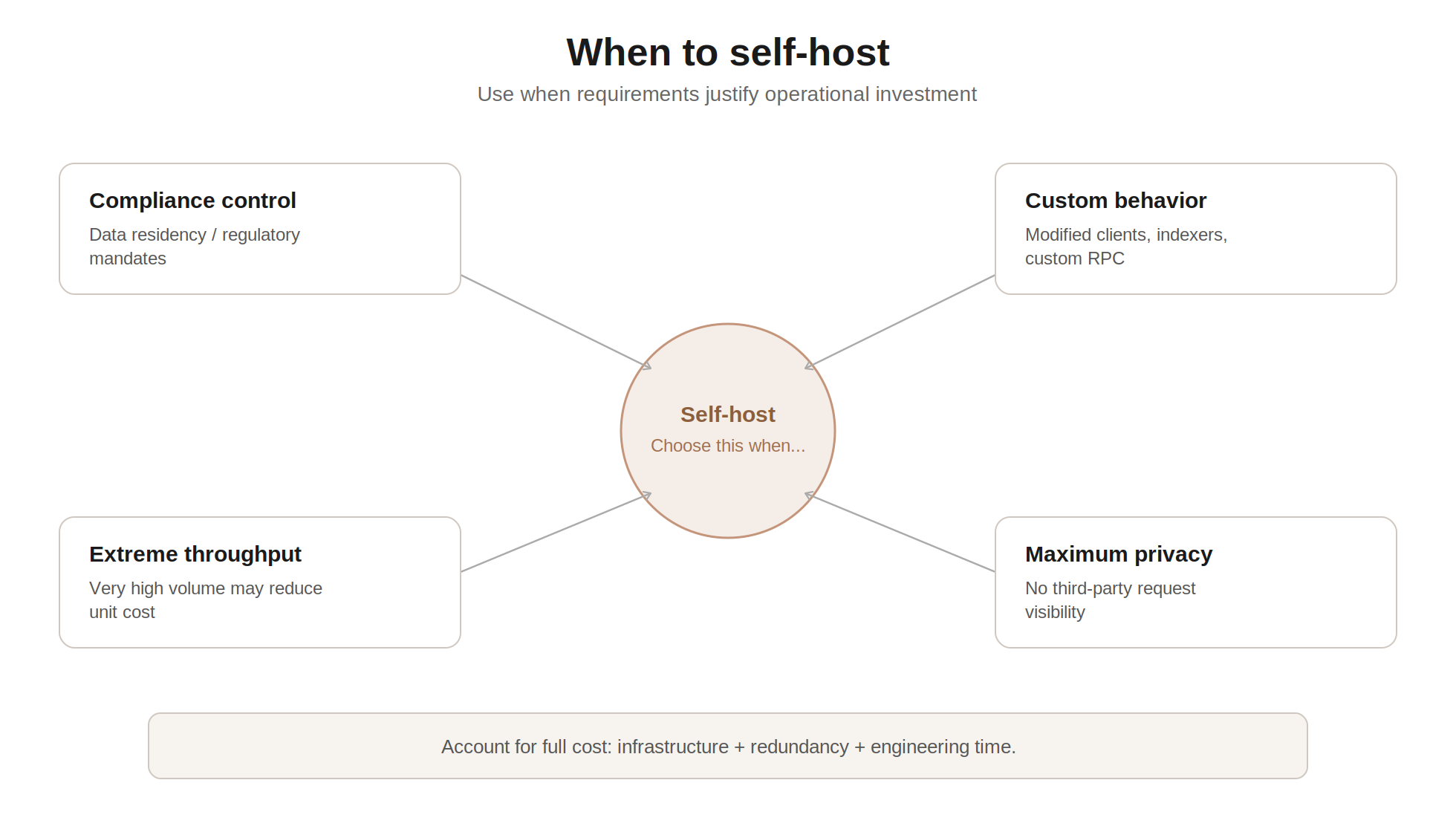
Self-hosting makes sense in specific scenarios where the operational cost is justified by the requirements.
Regulatory or compliance requirements sometimes mandate that blockchain data be processed on infrastructure you directly control. Financial institutions, government agencies, and organizations in highly regulated industries may not be permitted to route blockchain requests through third-party providers. In these cases, self-hosted nodes within your own data center or private cloud are a regulatory necessity, not a preference.
Custom node configurations are required for specialized use cases. If you need to run a modified client with custom indexing, non-standard RPC methods, or protocol-level instrumentation, you need your own nodes. Managed providers operate standardized node configurations optimized for the broadest set of use cases. Custom requirements often cannot be accommodated on shared infrastructure.
Extremely high request volumes can make self-hosting more cost-effective at scale. If your application makes billions of RPC requests per month across a small number of chains, the unit economics of running your own nodes may be favorable compared to per-request pricing from a provider. However, this calculation must account for the full cost of operations: hardware, bandwidth, engineering time for maintenance and on-call, redundancy infrastructure, and the opportunity cost of engineers managing nodes instead of building product.
Maximum privacy is another consideration. When you use a third-party provider, your RPC requests pass through their infrastructure. The provider could theoretically log which addresses you query, which contracts you interact with, and when. Self-hosted nodes eliminate this exposure entirely. For applications handling sensitive financial data or operating in adversarial environments, this privacy guarantee can be decisive.
When to Use a Managed Provider
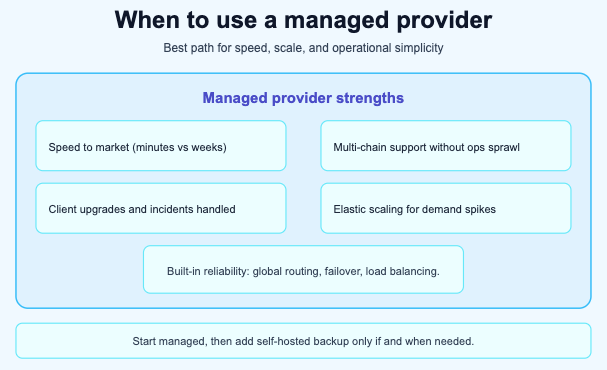
For the vast majority of development teams and use cases, a managed provider is the right starting point and often the right long-term solution.
Speed to market is the most common driver. Setting up a self-hosted Ethereum node takes days to weeks for initial sync, plus additional time for configuration, monitoring, and hardening. Creating a Quicknode endpoint takes minutes. For teams iterating on product-market fit, spending weeks on infrastructure before writing a single line of application code is a poor use of limited runway.
Multi-chain support becomes impractical to self-host. If your application operates across 5, 10, or 80+ chains, running and maintaining separate node infrastructure for each one requires a dedicated operations team. A managed provider gives you access to all supported chains through a single platform and API, with consistent performance and reliability across all of them.
Operational expertise is often the bottleneck. Running blockchain nodes requires knowledge of specific client software, consensus mechanisms, disk management, network configuration, and chain-specific quirks. Most development teams do not have (and should not need) this specialized expertise. A managed provider's operations team handles client upgrades, hard fork preparations, disk capacity planning, and incident response, freeing your engineers to focus on your application.
Elastic scaling handles variable demand. Applications experience traffic spikes during NFT mints, token launches, market volatility, and viral moments. Self-hosted infrastructure must be provisioned for peak load (expensive when idle) or risk degradation during spikes. Managed providers scale automatically to handle variable demand without over-provisioning.
Built-in reliability features like geographic distribution, automatic failover, load balancing, and redundancy are included with managed providers. Achieving the same level of reliability with self-hosted infrastructure requires significant additional investment in redundant nodes, monitoring systems, alerting, and failover automation.
The Hybrid Approach
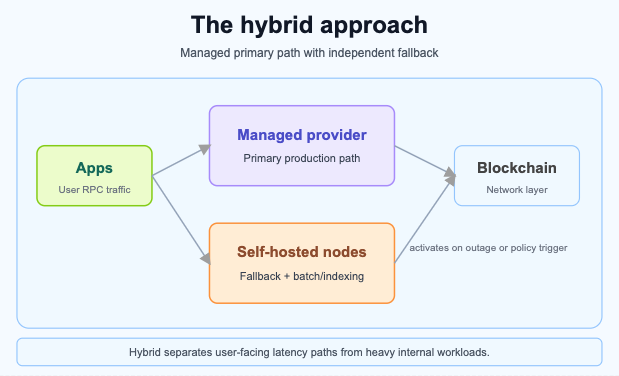
Many mature organizations adopt a hybrid strategy that captures the benefits of both approaches. The primary production traffic routes through a managed provider for reliability, performance, and global distribution. Self-hosted nodes serve as a secondary fallback that activates if the primary provider experiences issues. This architecture provides the operational simplicity of a managed provider for day-to-day operations with the independence and resilience of self-hosted infrastructure as a safety net.
The hybrid approach also works for separating workloads. Latency-sensitive, user-facing requests go through the managed provider's globally distributed endpoints. Heavy batch processing, historical data analysis, or custom indexing workloads run against self-hosted nodes where you can control resource allocation without impacting production traffic or incurring per-request costs.
Cost Comparison
The total cost of self-hosting extends well beyond hardware. A realistic accounting includes server or cloud compute costs (CPU, RAM, storage, bandwidth), engineering time for initial setup (typically 2-4 weeks for a production-ready single-chain deployment), ongoing maintenance (client updates, security patches, disk management, monitoring), on-call coverage (someone must respond when nodes go down at 3 AM), redundancy infrastructure (at least 2x the base cost for failover capability), and scaling for multiple chains (multiply everything by the number of chains supported).
Managed provider costs are typically usage-based (per request or per compute unit) with predictable monthly bills. The apparent per-request cost may seem higher than the marginal cost of a self-hosted request, but the all-in cost comparison including engineering time and operational overhead almost always favors the managed provider for teams with fewer than 5-10 dedicated infrastructure engineers.
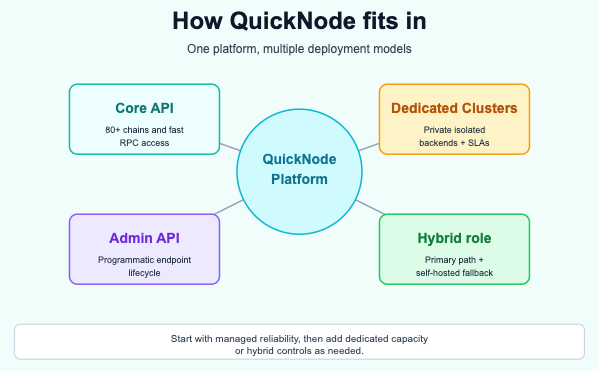
How Quicknode Fits In
Quicknode is built for teams that want production-grade blockchain infrastructure without the operational burden of running it themselves. The Core API provides instant RPC access to 80+ chains with 99.99% uptime, globally distributed endpoints, and response times 2.5x faster than competitors. For teams that need the control and isolation of dedicated infrastructure without managing it, Quicknode's Dedicated Clusters provide private, isolated node backends with guaranteed performance SLAs and full operational management by Quicknode's team.
For teams running hybrid architectures, Quicknode serves as the high-availability primary provider while self-hosted nodes provide independence and fallback capability. Quicknode's platform also supports programmatic endpoint management through the Admin API, enabling teams to automate provisioning and configuration as part of their infrastructure-as-code workflows.
What is the difference between building and buying blockchain infrastructure?
Building means you operate the full stack yourself: provisioning servers, running blockchain client software, syncing chains from genesis, and owning every update and failover event. Buying means you consume a managed RPC endpoint from a provider that runs that stack for you. The table below summarizes how the two models compare across the decisions that matter most.
Dimension
Self-host (build)
Managed provider (buy)
Time to first request
Days to weeks of sync and setup
Minutes to create an endpoint
Operational burden
You own updates, scaling, and on-call
Provider handles updates and uptime
Multi-chain support
A separate stack per chain
One API across 80+ chains
Control and privacy
Full control over config and data
Standardized, shared configuration
Cost model
Large fixed cost plus engineering time
Predictable usage-based pricing
Reliability
You build redundancy and failover
Built-in failover and distribution
How does build vs buy affect reliability and uptime?
Reliability is where the gap between the two models is widest. Reaching strong node reliability and high availability on self-hosted infrastructure means running redundant nodes, health checks, and automatic failover across regions. That is exactly why infrastructure redundancy matters, and it is engineering work you either build yourself or inherit from a provider that has already solved it.
How does the decision change as you scale to more chains?
A single-chain hobby node is manageable. The calculus shifts quickly once you expand across the Web3 infrastructure stack and add networks, because each new chain is another client to operate, sync, and patch. Buying a managed endpoint for a chain like Ethereum adds a network without adding headcount, while self-hosting multiplies operational load by the number of chains you support.
How do you migrate between self-hosted and managed infrastructure?
Migration is usually low risk because both models speak the same JSON-RPC interface. Teams running a node today can point an application at a managed Core API endpoint by swapping a URL, then keep the self-hosted node as a fallback. Moving the other direction works the same way, which is what makes a hybrid setup a safe default.
Frequently Asked Questions
Is it cheaper to build or buy blockchain infrastructure?
For a single hobby node, building can be cheaper. For production workloads the math usually favors buying once you add redundant hardware, bandwidth, monitoring, on-call staff, and the engineering time to keep uptime where users expect it.
How long does it take to set up self-hosted nodes?
Expect days to weeks per chain. Initial sync from genesis can take days for Ethereum and longer for archive nodes, and that is before you add monitoring, redundancy, and hardening. A managed endpoint is ready in minutes.
Can you use self-hosted and managed infrastructure together?
Yes. Many teams run a hybrid setup where a managed provider serves primary production traffic and self-hosted nodes act as a fallback or handle private, heavy batch workloads. Both speak the same RPC interface, so routing between them is straightforward.
Does using a managed provider mean losing control of your data?
You give up some control over node configuration and request privacy, since calls pass through the provider. For most applications that tradeoff is acceptable, but teams with strict regulatory or privacy requirements may keep sensitive workloads on self-hosted nodes.
When does self-hosting actually make sense?
Self-hosting is justified when you have regulatory mandates, need custom node configurations, run extremely high request volumes on a few chains, or require maximum privacy, and you have the DevOps team to operate it reliably.