Answers>Learn about scalability & performance>Why blockchains slow down
Why blockchains slow down
// Tags
blockchain slowblockchain performance
TL;DR: Blockchains slow down when demand for block space exceeds the network's processing capacity. The most common causes are network congestion (too many transactions competing for limited block capacity), state bloat (growing storage requirements that increase the computational cost of processing each block), consensus overhead (communication costs that scale with validator count), and infrastructure limitations (slow nodes, high-latency RPC endpoints, and inefficient data pipelines). Slowdowns manifest as longer confirmation times, higher fees, stale data in applications, and degraded user experience. Some causes are inherent to blockchain design, while others can be mitigated with better infrastructure.
The Simple Explanation
"Slow" means different things depending on who is asking. For an end user submitting a transaction, slow means waiting minutes or hours for confirmation instead of seconds. For a developer running a data pipeline, slow means falling behind the chain tip and serving stale data. For a DeFi trader, slow means receiving price updates late and missing arbitrage opportunities. Each type of slowdown has different root causes and different solutions.
At the protocol level, blockchains have hard performance ceilings determined by their consensus mechanism, block parameters, and execution environment. These ceilings exist by design, not by accident. They are the price of decentralization and security. When demand pushes against these ceilings, the network does not crash. It degrades gracefully by increasing fees (pricing out lower-value transactions) and extending confirmation times (making users wait longer). But from the user's perspective, "graceful degradation" still feels slow.
At the infrastructure level, the blockchain itself might be performing normally, but the tools your application uses to interact with it might be the bottleneck. A slow or overloaded RPC endpoint adds latency to every request. A polling-based data pipeline introduces delays between block production and data availability. An under-provisioned node drops behind the chain tip. These infrastructure-level slowdowns are often more impactful (and more fixable) than protocol-level ones.
Cause
What happens
Who can address it
Network congestion
Demand exceeds block space, so fees and wait times rise
Users (fees) and app design
State bloat
Growing state raises the cost of processing every block
Protocol and core developers
Consensus overhead
Validator communication adds unavoidable latency
Protocol design
Infrastructure bottlenecks
Slow RPC, polling, and distant nodes add delay
Developers, directly
Network Congestion
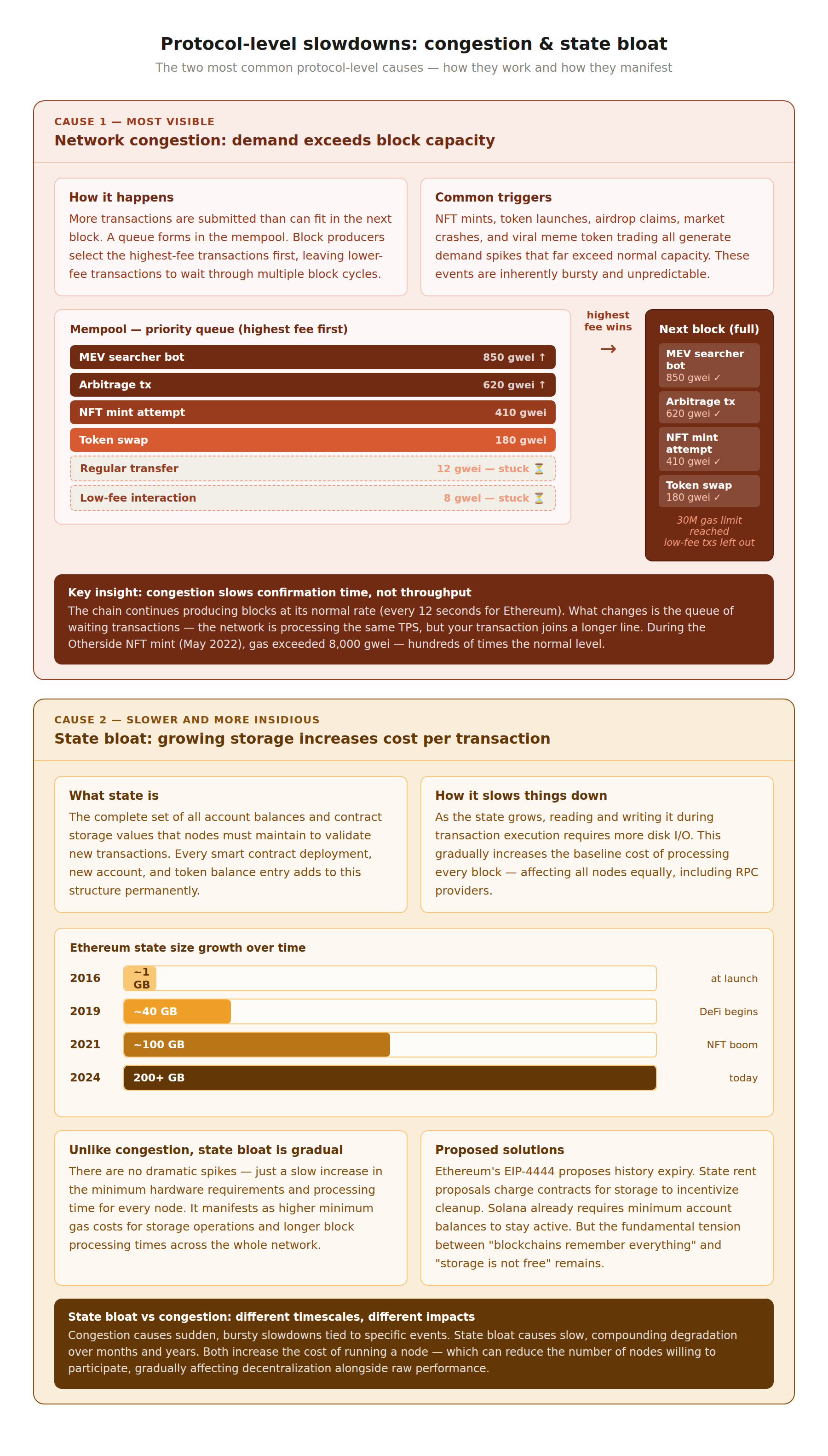
Network congestion is the most common and most visible cause of blockchain slowdowns. When more transactions are submitted than can fit in the next block, a backlog forms in the mempool. Block producers select the highest-fee transactions first, leaving lower-fee transactions waiting. During severe congestion, the mempool can contain hundreds of thousands of pending transactions, with confirmation times stretching from seconds to hours.
Congestion is inherently bursty. Most of the time, popular blockchains operate well below their capacity limits, and transactions confirm quickly at low cost. But specific events trigger demand spikes that overwhelm the network. NFT mints, token launches, airdrop claims, market crashes, and viral meme token trading all generate transaction surges that far exceed normal levels. During the Yuga Labs Otherside mint in May 2022, Ethereum gas prices exceeded 8,000 gwei, hundreds of times the normal level.
The key insight is that congestion slows down individual transaction confirmation but does not reduce the network's throughput. The chain continues producing blocks at its normal rate (every 12 seconds for Ethereum, every 400ms for Solana). What changes is the wait time before a transaction gets included in a block. The network is processing the same number of transactions per second; it is the queue of waiting transactions that grows.
State Bloat
State bloat is a slower, more insidious form of blockchain degradation. Every smart contract deployment, every new account, every token balance entry adds to the blockchain's state, the set of all current account balances and contract storage values that nodes must maintain in memory or on disk to validate new transactions. As the state grows, the computational cost of reading and writing state during transaction execution increases.
On Ethereum, the state trie has grown from nearly nothing at launch to hundreds of gigabytes. Every transaction that reads or writes state must traverse this data structure, and the larger it gets, the more disk I/O each operation requires. This affects all nodes equally, including those operated by RPC providers. State bloat does not cause dramatic, sudden slowdowns like congestion does. Instead, it gradually increases the baseline cost of processing every block, which can manifest as slightly longer block processing times, higher minimum gas costs for state-accessing operations, and increased hardware requirements for running nodes.
Several chains have implemented or proposed state management solutions. Ethereum's EIP-4444 proposes history expiry (dropping old block data from full nodes). State rent proposals would charge contracts for the storage they consume, incentivizing cleanup. Solana's account rent system already requires minimum balances for accounts to remain active. These approaches attempt to manage state growth, but the fundamental tension between "blockchains remember everything" and "storage is not free" remains.
Consensus Overhead
The consensus mechanism is the process by which validators agree on which transactions to include in the next block and in what order. This process inherently adds latency because validators must communicate with each other, and communication takes time. The more validators participate in consensus, the more messages must be exchanged, and the longer consensus takes.
This is one dimension of the blockchain trilemma. A network with 4 validators can reach consensus very quickly (low latency) but is highly centralized. A network with 400,000 validators (like Ethereum) has strong decentralization but requires a sophisticated consensus protocol with multiple communication rounds, attestation periods, and finality checkpoints that add minutes of latency between block inclusion and finality.
Some chains use leader-based consensus where a single validator proposes a block and others validate it, reducing the communication overhead but introducing a single point of latency (the leader). Others use committee-based consensus where a randomly selected subset of validators handles consensus for each slot, balancing decentralization with speed. The choice of consensus mechanism directly determines the network's baseline latency floor, the minimum time between transaction submission and finality that cannot be reduced regardless of how fast the underlying hardware is.
Infrastructure Bottlenecks
For most developers, the slowdowns they experience day-to-day are not protocol-level at all. They are infrastructure-level. Your application's perceived blockchain speed is determined by the weakest link in its data path: the RPC endpoint it connects to, the data pipeline that feeds its database, and the processing logic that transforms raw blockchain data into application state.
A shared, public RPC endpoint with hundreds of other users competing for capacity adds unpredictable latency to every request. Rate limiting throttles your request volume during peak usage, exactly when you need it most. Geographic distance between your application servers and the nearest node increases round-trip time for every call. An under-provisioned node that falls behind the chain tip serves stale data, making your application's state lag behind reality.
Polling-based data pipelines introduce artificial latency equal to the polling interval. If your indexer checks for new blocks every 10 seconds, it is always 0-10 seconds behind the chain tip even under perfect conditions. During congestion, when blocks are full and processing time increases, the polling interval becomes the bottleneck that prevents your application from keeping up.
These infrastructure bottlenecks are the most actionable cause of blockchain slowdowns because they are the ones developers can directly address. Upgrading to a dedicated, high-performance RPC provider reduces endpoint latency. Switching from polling to streaming eliminates artificial pipeline delays. Using geographically distributed infrastructure reduces round-trip times. Dedicating isolated node resources eliminates noisy-neighbor effects.
How Quicknode Addresses Blockchain Slowdowns
Quicknode's infrastructure is designed to minimize or eliminate the infrastructure-level bottlenecks that cause applications to experience blockchain slowdowns. The Core API runs on a globally distributed network across 14+ regions and 5+ cloud providers, automatically routing requests to the nearest, fastest available node. Response times average 2.5x faster than competitors, with 99.99% uptime SLAs ensuring consistent availability even during network congestion events. Dedicated Clusters provide isolated infrastructure that eliminates noisy-neighbor effects, giving latency-sensitive applications predictable performance regardless of what other users are doing.
Quicknode Streams eliminates the polling bottleneck entirely by delivering blockchain data via push-based streaming with guaranteed delivery in finality order. There is no polling interval, no artificial delay, and no risk of missed blocks. During congestion, when blocks are larger and contain more transactions, Streams scales its delivery to match the increased data volume. Configurable batching and compression optimize throughput for historical backfills and high-volume chains. For Solana, Quicknode's Yellowstone gRPC provides the lowest-latency data access available, using binary Protocol Buffers instead of JSON to minimize serialization overhead on a chain where every millisecond matters.
What is the difference between a slow blockchain and a slow dapp?
These feel the same to a user but have different causes. A slow blockchain is a protocol problem: congestion, consensus timing, or state size are limiting how fast the network confirms transactions. A slow dapp is usually an infrastructure problem: the chain is fine, but a distant or overloaded endpoint is adding delay on top. Comparing throughput versus latency is the clearest way to tell which one you are actually dealing with.
Aspect
Protocol level
Infrastructure level
Source
Consensus, block limits, state size
RPC endpoint, data pipeline, node location
Who controls it
The network and core developers
You, the developer
How fixable
Hard, needs protocol upgrades
Easy, change provider or pattern
Example
High gas during an NFT mint
A slow public endpoint adding latency
What causes sudden spikes in blockchain congestion?
Congestion is bursty rather than constant. Token launches, NFT mints, airdrop claims, market crashes, and viral trading all flood the network with transactions in a short window, and fees climb as users bid for limited block space. Understanding what causes blockchain congestion helps you plan for these events instead of being surprised by them.
How do Layer 2s and scaling reduce slowdowns?
Layer 2 networks move most transactions off the base chain and settle them in batches, which dramatically increases throughput and lowers fees for everyday activity. Running your app on a Layer 2 blockchain is one of the most effective ways to avoid base layer congestion while keeping the security of the underlying network.
Which slowdowns can developers actually fix?
Protocol level limits are mostly out of your hands, but infrastructure slowdowns are not. You can move to a faster provider, place nodes closer to your users, and replace polling with push based delivery. Switching from polling to streaming alone removes the artificial delay baked into interval based pipelines.
Frequently Asked Questions
Does congestion mean the blockchain is processing fewer transactions?
No. The chain keeps producing blocks at its normal rate and processing the same throughput. What grows during congestion is the queue of pending transactions, which is why individual confirmations take longer and fees rise.
Does decentralization make blockchains slower?
It can. More validators means more communication to reach agreement, which raises the baseline latency. This trade-off between speed and decentralization is explored in detail in decentralization versus performance.
Can a faster RPC provider fix a slow application?
Often, yes. If the chain is healthy but your dapp feels slow, the bottleneck is usually your endpoint. Reducing RPC latency with a closer, dedicated provider can remove most of the delay your users notice.
Is state bloat something I can solve as a developer?
Not directly. State bloat is a protocol level issue managed through upgrades like history expiry and account rent. You can reduce its impact by caching read heavy data and avoiding unnecessary on chain storage in your contracts.
Why do fees go up when a blockchain slows down?
Block space is limited, so when demand spikes users bid higher fees to get included sooner. Higher fees are the market clearing mechanism that decides whose transaction makes it into the next block.