Answers>Learn about blockchain nodes>Full node vs archive node
Full node vs archive node
// Tags
full node vs archive nodeethereum archive node
TL;DR: A full node stores the current state of the blockchain and validates all new transactions and blocks, but prunes older historical data to save storage. An archive node does everything a full node does, plus it retains the complete historical state of the chain from the genesis block forward. The type you need depends on whether your application requires current data or access to any historical state at any point in time.
The Simple Explanation
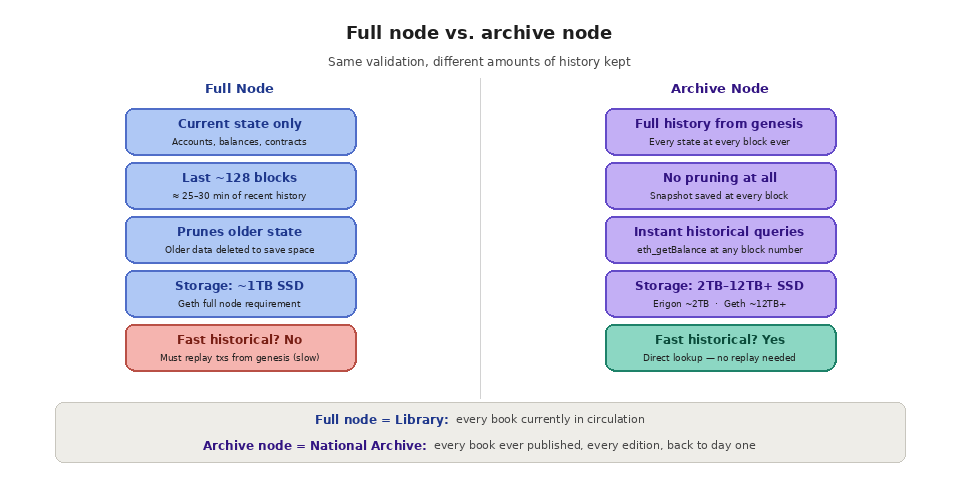
Every blockchain node downloads and verifies the chain, but not every node keeps the same amount of data around. Think of it like a library versus an archive. A full node is the library: it has every book currently in circulation and can tell you what is on the shelves right now. An archive node is the national archive: it has every book that was ever published, every edition, and every out-of-print manuscript going back to day one.
On Ethereum, a full node stores the current state of all accounts, balances, and smart contracts, along with enough recent block history to verify the chain's integrity. By default, most Ethereum clients keep the last 128 blocks of state data readily accessible, which covers roughly the last 25 to 30 minutes of network activity. Anything older than that gets pruned to save disk space. The full node can still technically reconstruct older states by replaying transactions from the genesis block, but that process is extremely slow and computationally expensive.
An archive node skips the pruning entirely. It stores a snapshot of the entire blockchain state at every single block since the chain's inception. This means you can query the balance of any wallet, the storage of any smart contract, or the output of any transaction at any point in the chain's history, and get an instant response. No replaying required. The tradeoff is storage. A full Ethereum node running Geth needs around 1TB of SSD space. An archive node running Geth needs over 12TB, and that number grows every day. Erigon, a more storage-efficient client, brings archive requirements down to roughly 2TB, but it is still significantly more than a pruned full node.
What is the difference between a full node and an archive node?
Both node types validate the chain and store the current state, but only an archive node keeps every historical state snapshot. The table below summarizes the practical differences. If you are still deciding which node type to operate, our overviews of what a blockchain node is and running a node versus using an RPC provider add helpful context.
Attribute
Full node
Archive node
Historical state
Pruned after ~128 blocks
Retained from genesis
Storage (Ethereum, Geth)
About 1TB
Over 12TB (about 2TB on Erigon)
Historical state queries
Return a missing trie node error
Instant at any block height
Sync time
Hours to days
Days to weeks
Best for
Wallets, dapps, payments, real-time reads
Explorers, analytics, audits, tracing
When You Need a Full Node
Full nodes are the workhorses of any blockchain network. They validate every new block, enforce consensus rules, reject invalid transactions, and serve as trust anchors for lightweight clients that do not store the full chain. If you are building a wallet, a dapp that only needs current balances and recent transaction data, or a service that submits transactions to the network, a full node is sufficient.
Most production applications fall into this category. A decentralized exchange needs to know current token balances and execute swaps in real time. A payment processor needs to verify that incoming transactions are valid and confirmed. A wallet needs to display current balances and broadcast new transactions. None of these use cases require querying what a specific account's balance was 500,000 blocks ago. Current state is enough, and a full node delivers it with dramatically lower hardware requirements than an archive node.
Full nodes also play a critical role in network health. The more independent full nodes running on a blockchain, the more decentralized and resilient the network becomes. Each full node independently verifies the chain, so no single node or group of nodes can unilaterally alter the record. Running a full node is the most direct way to participate in and support a blockchain's security model.
When You Need an Archive Node
Archive nodes become essential when your application depends on historical blockchain data. If you are building a block explorer that lets users look up any transaction or account state from any point in the chain's history, you need archive access. If you are running analytics that track how token holdings, smart contract states, or DeFi protocol metrics have changed over time, you need archive access. If you are forking mainnet using development tools like Hardhat or Foundry to simulate past conditions for testing, you need archive access.
Specific technical scenarios also demand archive nodes. Calling eth_getBalance or eth_call at a historical block number (anything older than the last 128 blocks on most clients) requires archive data. Debugging a failed transaction from weeks ago by tracing its execution requires archive data. Reconstructing the state of a lending protocol at a specific block to audit a liquidation event requires archive data. Without an archive node, these queries will return a "missing trie node" error because the data has been pruned.
The audience for archive nodes is narrower but critical: blockchain analytics platforms, forensic investigators, protocol auditors, indexing services like The Graph, and any application that needs to answer questions about the past, not just the present.
Why do historical queries fail on a full node?
A full node prunes state older than roughly the last 128 blocks, so calling eth_getBalance or eth_call at an older block returns a missing trie node error. The transaction record still exists, but the state at that moment was deleted to save space. Recovering it requires an archive node or a stored dataset, which is the core idea behind accessing historical blockchain data. This pruning is also why querying blockchain data at scale often needs more than a single full node.
How much storage does each node type need?
Storage is the biggest practical difference, and it depends on the chain and client. The table shows typical Ethereum figures. These numbers grow continuously, which is one reason many teams query historical state through a provider instead, as covered in real-time vs historical blockchain data.
Configuration
Approximate storage
Notes
Full node (Geth)
About 1TB
Prunes old state
Archive node (Geth)
Over 12TB
Stores every state snapshot
Archive node (Erigon)
Roughly 2TB
More storage-efficient client
The Storage and Cost Reality
Running your own archive node is a serious commitment. Beyond the 12TB+ storage requirement for Ethereum alone, you need high-performance SSDs (not HDDs) for acceptable query speed, and syncing an archive node from scratch can take weeks depending on your hardware and internet connection. If your node falls out of sync or crashes during the initial sync, you may need to start over. Multiply that by every chain your application supports, and the infrastructure burden scales quickly.
This is why most developers and teams rely on infrastructure providers rather than running archive nodes themselves. Quicknode includes archive data access across all plans, meaning you can query any historical state on any supported chain without managing the underlying storage or sync process. Whether you need the last 10 minutes of data or the full history back to genesis, Quicknode's Core API handles it through the same RPC endpoint. For teams that need dedicated, isolated infrastructure, Quicknode's Dedicated Clusters provide private archive node access with guaranteed uptime SLAs and predictable performance.
Can one endpoint serve both full and archive data?
Yes. Many providers route current-state requests to full nodes and historical-state requests to archive nodes behind a single URL, so you do not have to manage two setups. From the application side it is just one RPC endpoint that answers both recent and historical queries.
No. An archive node does everything a full node does and also keeps every historical state snapshot from genesis. A full node prunes old state to save disk space, so it cannot answer arbitrary historical state queries.
Do I need an archive node for my dapp?
Most dapps, wallets, and payment apps only need current state, so a full node is enough. You need archive access mainly for block explorers, analytics, audits, mainnet forking, and tracing historical transactions.
Why does eth_getBalance fail at an old block?
Because a full node has pruned the state for that block, the call returns a missing trie node error. Querying an archive node, which retains every state snapshot, resolves it.
How much does an Ethereum archive node store?
Around 12TB or more on Geth, compared to about 1TB for a full node. The storage-efficient Erigon client reduces archive storage to roughly 2TB, and all of these figures grow over time.
How do archive nodes relate to indexing?
Indexers often read historical data from archive nodes or backfilled datasets to build queryable databases. For how that layer works, see what blockchain indexing is.