Answers>Learn about blockchain nodes>What is a blockchain node?
What is a blockchain node?
// Tags
blockchain nodewhat is a nodefull node
TL;DR: A blockchain node is a computer running software that maintains a copy of the blockchain, verifies transactions, and relays data across the network. Nodes are the backbone of every blockchain. Without them, there is no network. Different types of nodes serve different purposes, from lightweight nodes that verify transactions to full archive nodes that store the entire history of the chain.
The Simple Explanation
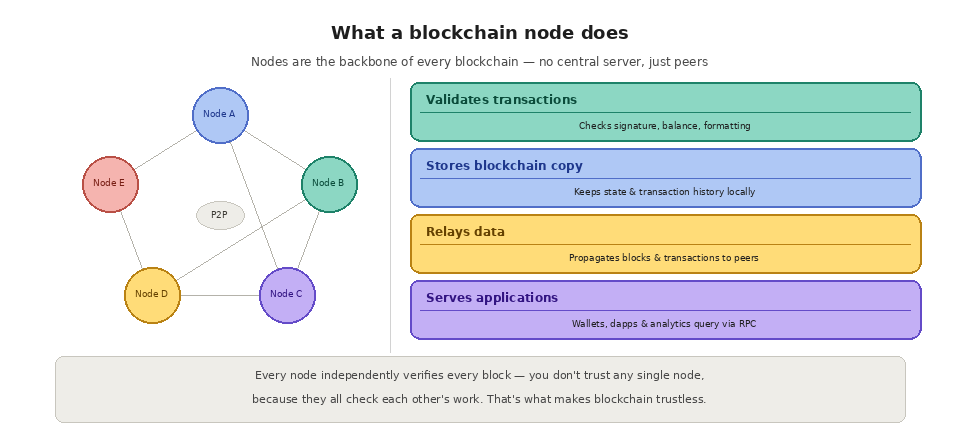
Every blockchain is a peer-to-peer network, which means there is no central server. Instead, thousands of individual computers (nodes) work together to keep the network running. Each node runs client software that connects it to other nodes, downloads a copy of the blockchain, validates new transactions and blocks according to the consensus rules, and shares data with the rest of the network.
When you send a transaction on Ethereum, Solana, or any other blockchain, your transaction does not go to a single company's server. It gets broadcast to the network and picked up by nodes. Those nodes check that the transaction is valid (correct signature, sufficient balance, proper formatting), include it in a block, and propagate the confirmed block across the network. Every node independently verifies every block, which is what makes blockchain trustless. You do not need to trust any single node because they all check each other's work.
Running a node is how you participate in the network at the most fundamental level. It is also how applications interact with the blockchain. When a wallet shows your balance, it is querying a node. When a dapp executes a smart contract, it is sending a transaction through a node. When an analytics platform tracks onchain activity, it is reading data from a node. Nodes are the gateway between your application and the blockchain
Types of Nodes
Not all nodes are created equal. The type of node you run (or connect to) depends on your use case, resources, and how much historical data you need access to.
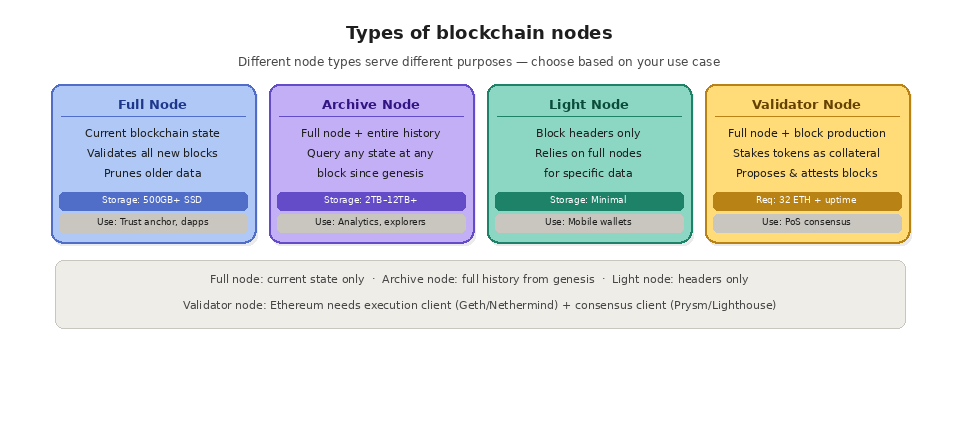
A full node stores the current state of the blockchain and validates all new transactions and blocks. It keeps enough recent history to verify the chain's integrity but prunes older data to save storage. On Ethereum, a full node typically requires a multi-core CPU, at least 8GB of RAM, and 500GB or more of SSD storage. Full nodes are the workhorses of the network. They enforce consensus rules, reject invalid blocks, and serve as a trust anchor for lightweight clients. Running a full node means you do not need to trust anyone else's version of the blockchain.
An archive node does everything a full node does, plus it stores the complete historical state of the blockchain from the genesis block to the present. This means you can query any account balance, smart contract state, or transaction at any point in history. Archive nodes are essential for blockchain analytics, historical data queries, debugging smart contracts, and building block explorers. The tradeoff is storage. An Ethereum archive node running Geth requires over 12TB of storage (and growing), while Erigon reduces that to around 2TB through a more efficient database design.
A light node (or light client) does not store the full blockchain. Instead, it downloads only block headers and relies on full nodes to provide specific data on demand. Light nodes can verify that a transaction was included in a block without processing the entire chain, making them suitable for mobile wallets and resource-constrained environments. They sacrifice some security guarantees for dramatically lower hardware requirements.
Validator nodes are full nodes that also participate in block production and consensus. On Proof of Stake networks, validators stake tokens as collateral and are responsible for proposing and attesting to new blocks. Running a validator typically requires additional hardware reliability, uptime guarantees, and (on Ethereum) at least 32 ETH staked. On Ethereum post-Merge, a validator node actually consists of two client software programs: an execution client (like Geth or Nethermind) and a consensus client (like Prysm or Lighthouse) that work together.
Why Running Your Own Node Is Hard
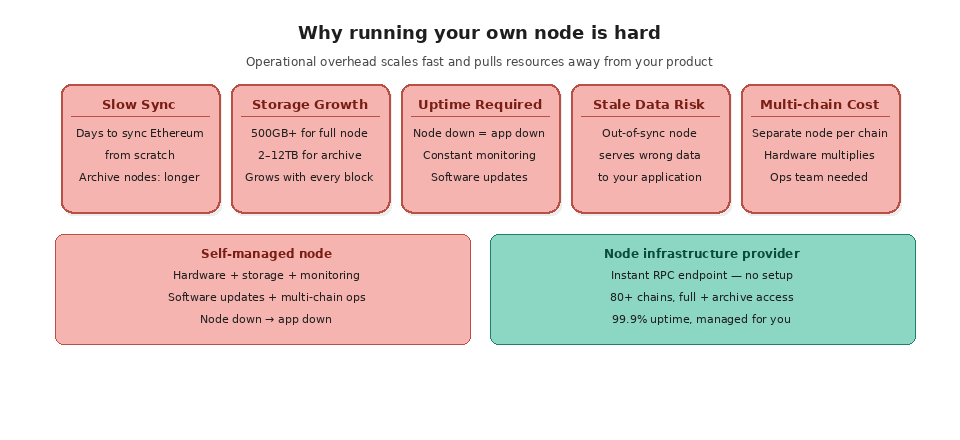
Running a blockchain node is not as simple as installing software and walking away. Syncing a full Ethereum node from scratch can take days depending on your hardware and internet speed. Archive nodes take even longer. Storage requirements grow constantly as new blocks are added to the chain. You need to monitor uptime, handle software updates, manage disk space, and troubleshoot issues when your node falls out of sync or encounters peer connectivity problems.
For developers building applications, the challenge is compounded. Your application needs consistent, low-latency access to blockchain data. If your node goes down, your app goes down. If your node falls behind on syncing, your app serves stale data. If you need access to multiple chains, you need to run and maintain separate nodes for each one. The operational overhead scales quickly and pulls development resources away from building your actual product.
This is exactly the problem that node infrastructure providers solve. Instead of managing your own hardware, software, and uptime, you connect to professionally managed nodes through RPC endpoints and focus on what you are actually building.
How Quicknode Fits In
Quicknode operates a globally distributed network of blockchain nodes optimized for performance, reliability, and scale. When you create a Quicknode endpoint, you get instant RPC, WebSocket, and (for supported chains) gRPC access to a node without managing any infrastructure yourself. Quicknode supports 80+ blockchain networks with both full node and archive data access included across all plans. This means you can query current state or historical data on any supported chain without running separate node types.
For developers who need more than basic RPC access, Quicknode provides Streams for real-time and historical blockchain data ingestion, dedicated clusters for enterprise-grade isolation and performance, and an ecosystem of marketplace add-ons that extend your node access with DeFi data, analytics, and security tools. Whether you are building a wallet that needs fast balance lookups, a DeFi protocol that needs reliable transaction submission, or an analytics platform that needs full historical data, Quicknode handles the node infrastructure so you can focus on your application.
For those who want to learn the fundamentals of running nodes firsthand, Quicknode also publishes detailed guides on setting up Geth, OpenEthereum, BNB Smart Chain, Stacks, and other clients from scratch.
What is the difference between a full node and an archive node?
The core difference is how much history each one keeps. A full node holds the current state and enough recent blocks to validate the chain, while an archive node retains every historical state since the genesis block. Archive nodes answer questions about balances or contract storage at any past block, which full nodes cannot. The table below summarizes the main node types, and you can dig deeper in the guide on full node and archive node differences.
Node type
What it stores
Typical storage
Best for
Full node
Current state and recent history
500 GB or more
Verifying the chain yourself
Archive node
Complete historical state
2 TB to 12 TB or more
Analytics, explorers, debugging
Light node
Block headers only
A few GB
Mobile and embedded wallets
Validator node
Full state plus consensus duties
500 GB or more
Securing a Proof of Stake chain
Should you run your own node or use a provider?
Running your own node gives you maximum control and privacy, but it comes with real operational cost: hardware, syncing time, monitoring, upgrades, and on-call maintenance when something breaks. For learning, experimentation, or staking, this can be worthwhile. You can compare the trade-offs in detail in the breakdown of running your own node versus using a managed provider.
For production applications, most teams use a provider because consistent uptime and low latency matter more than self-hosting. Node reliability directly determines whether your app stays online, serves fresh data, and handles traffic spikes without manual intervention.
How do you connect to a blockchain node?
Applications connect to a node through an RPC endpoint, which is a URL that accepts standardized requests to read data or submit transactions. Your code sends a request such as getting a balance or sending a transaction, the node processes it against its copy of the blockchain, and returns a response. Understanding how RPC requests work helps you design efficient, resilient applications.
Frequently Asked Questions
Is a node the same as a miner or validator?
Not exactly. Every miner and validator runs a node, but not every node is a miner or validator. A plain node stores the ledger and validates data, while miners (Proof of Work) and validators (Proof of Stake) are specialized nodes that also produce new blocks and earn rewards.
Do I need my own node to build a dapp?
No. You can build a full application using a managed RPC provider, which removes the need to host and maintain node hardware. Most production dapps connect to a provider so they get reliable, low-latency access across many chains without operational overhead.
How much does it cost to run a node?
Costs vary by chain and node type. A full node needs a capable machine and fast SSD, while an archive node can require several terabytes of high-speed storage. On top of hardware, you pay for bandwidth, electricity or cloud fees, and the engineering time to keep it synced and updated.
What software does a node run?
Each network has its own client software. Ethereum uses execution clients like Geth, Nethermind, and Erigon paired with consensus clients like Prysm or Lighthouse. Bitcoin commonly uses Bitcoin Core, and Solana runs the Agave validator client. Client diversity helps keep a network resilient.
Can a node fall out of sync?
Yes. A node can lag behind the chain tip due to slow hardware, network issues, or downtime, and an out-of-sync node serves stale data. This is one of the main reasons production teams rely on monitored, professionally operated nodes.