Answers>Learn about blockchain nodes>Why node reliability matters
Why node reliability matters
// Tags
node reliabilityblockchain uptime
TL;DR: Node reliability is the measure of how consistently and accurately a blockchain node responds to requests without downtime, errors, or stale data. For any application that reads from or writes to a blockchain, unreliable node infrastructure means failed transactions, incorrect balances, missed events, and broken user experiences. In production environments, node reliability is not a nice-to-have. It is the foundation everything else depends on.
The Simple Explanation
Every interaction your application has with a blockchain flows through a node. When a user checks their wallet balance, a node answers that query. When someone submits a swap on a decentralized exchange, a node broadcasts that transaction. When your backend listens for smart contract events, a node delivers those events. If the node is slow, down, or returning outdated data, your application breaks in ways that directly impact your users and your revenue.
Think of node reliability the way you would think about database uptime for a traditional web application. If your database goes offline, your app cannot read or write data. Users see errors, transactions fail, and trust erodes. Blockchain nodes serve the same function as your database layer, except the data they serve is financial in nature. A stale balance could cause a user to overdraw. A dropped transaction could mean a missed trade. A delayed event could trigger incorrect liquidations in a DeFi protocol. The stakes are higher, and the tolerance for failure is lower.
What Unreliable Nodes Actually Cost You
The consequences of poor node reliability show up in multiple ways, and most of them are not immediately obvious until something goes wrong in production.
Stale data is one of the most dangerous failure modes. If your node falls behind the chain's tip (the most recently confirmed block), it starts serving outdated state. Your application might show a user a balance that no longer exists, display a transaction as pending when it has already been confirmed, or miss a critical smart contract event entirely. On fast chains like Solana where blocks are produced every 400 milliseconds, even a few seconds of sync delay can mean your application is multiple blocks behind reality.
Failed transactions are another major cost. When you submit a transaction through a node, that node needs to broadcast it to the network's mempool (or equivalent). If the node is overloaded, disconnected from peers, or improperly configured, the transaction might never reach validators. The user thinks their transaction was submitted, but it never gets included in a block. On high-throughput chains or during periods of network congestion, this can happen frequently with underpowered or poorly maintained nodes.
Missed events impact any application that depends on real-time blockchain data. If your node drops WebSocket connections, fails to deliver event logs, or skips blocks during a reorganization, your application loses data. For indexers, analytics platforms, and any system that needs a complete record of onchain activity, even a single missed block can corrupt your dataset and require a full resync.
Latency affects competitive use cases directly. In DeFi trading, MEV extraction, and arbitrage, milliseconds matter. A slow node means your transaction arrives after someone else's, and the opportunity is gone. For applications where timing is less critical, high latency still degrades user experience. Users expect wallet balances to update instantly and transactions to confirm quickly. Sluggish node responses make your application feel broken even when the blockchain itself is performing fine.
What Makes a Node Reliable
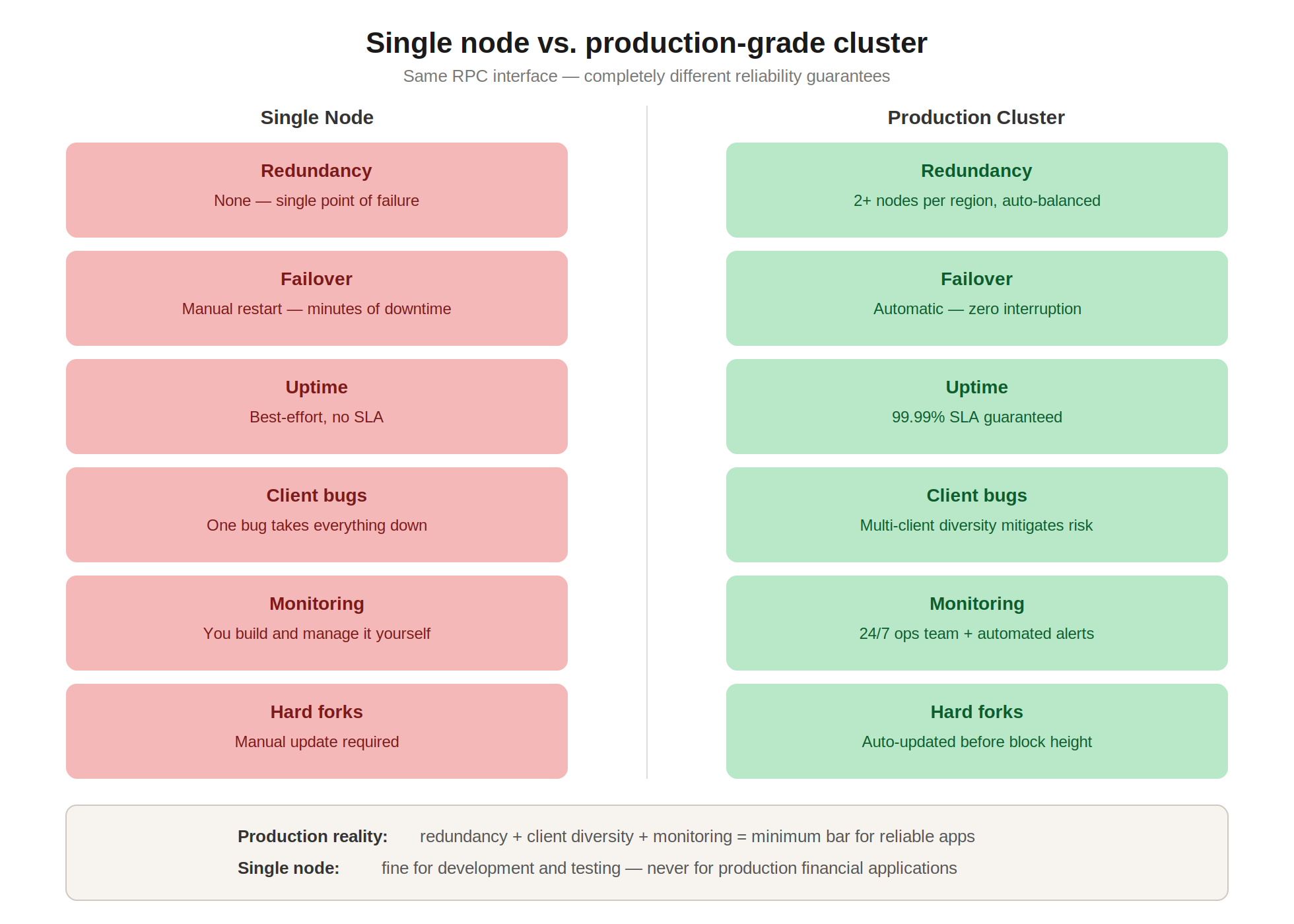
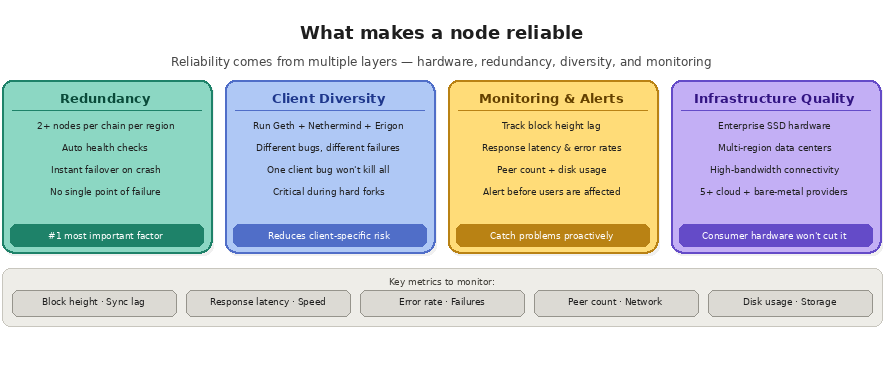
Reliability comes from multiple layers: hardware quality, software configuration, network connectivity, redundancy, and operational monitoring. A single node running on consumer hardware with a residential internet connection will never match the reliability of a professionally managed cluster of nodes distributed across multiple data centers and cloud providers.
Redundancy is the most important factor. If a single node goes down (due to a crash, a disk failure, or a client bug), a redundant system fails over to a healthy node without any interruption to your application. Without redundancy, a single point of failure can take your entire application offline. Production-grade infrastructure typically runs two or more nodes of the same chain within a region, with automatic health checks and traffic routing.
Client diversity matters too. Different blockchain client implementations (Geth vs. Nethermind vs. Erigon on Ethereum, for example) have different performance characteristics, different bugs, and different failure modes. Running multiple client implementations reduces the risk that a bug in one client takes down your entire infrastructure. This is especially important during hard forks and protocol upgrades, when client-specific issues are most likely to surface.
Monitoring and alerting are essential for catching problems before they impact users. A well-operated node infrastructure continuously tracks metrics like block height (to detect sync lag), response latency, error rates, peer count, and disk usage. When any metric crosses a threshold, automated alerts trigger investigation or failover before the issue reaches production.
How is node reliability measured?
Reliability is not a single number but a set of signals that, together, describe whether a node can be trusted in production. The table below shows the metrics that matter most, what each one tells you, and the range a production-grade setup should hold.
Metric
What it tells you
Production target
Uptime SLA
Share of time the endpoint is available
99.9% or higher
Error rate
Share of requests returning errors
Below 0.1%
Sync lag
Distance behind the chain tip
Within 0 to 1 block
Response latency (p99)
Slowest 1% of responses
Under 500 ms
Peer count
Healthy network connectivity
Stable above the client minimum
Uptime is the headline number, but a node can be "up" and still unreliable if it is lagging the tip or returning errors. Track these signals continuously rather than spot-checking them. For the full picture of how to instrument an endpoint, see monitoring blockchain infrastructure.
What causes a blockchain node to fail?
Nodes fail for both internal and external reasons. Internally, a disk filling up, a memory leak, or a client software bug can crash or stall a node. Externally, network partitions, peer loss, and surges of traffic during network congestion can overwhelm an underprovisioned node. Protocol upgrades and hard forks are especially risky moments, since a bug specific to one client can take down every node running it. Understanding the common blockchain failure modes helps you design infrastructure that degrades gracefully instead of going dark.
How does failover improve node reliability?
Failover is the mechanism that turns several individual nodes into one reliable service. Health checks watch each node, and when one degrades or goes offline, traffic is automatically rerouted to a healthy node so your application never sees the outage. This is the core of high availability, and it depends on infrastructure redundancy: running more than one node so there is always a backup ready. See what failover is for how seamless switching works in practice.
Should you run your own node or use a provider?
Running your own node gives you full control but puts the entire reliability burden on your team: hardware, redundancy, monitoring, upgrades, and 24/7 on-call coverage. A managed provider absorbs that operational load and gives you a distributed, redundant fleet from the first request. The right choice depends on your scale, budget, and tolerance for operational risk, and it can differ by workload, since an archive node is far heavier to self-host than a full node. See build vs buy for a framework to make the call.
How Quicknode Delivers Reliability
Quicknode's infrastructure is purpose-built for production reliability at scale. The platform processes billions of API requests daily across 80+ blockchain networks with a 99.99% uptime SLA. This reliability comes from a globally distributed architecture spanning 14+ regions and 5+ cloud and bare-metal providers, multiple client implementations per chain, automatic failover and load balancing, and 24/7 monitoring by a dedicated blockchain operations team.
Quicknode uses usage-specific node clusters, meaning that traffic is routed to nodes optimized for the type of request being made. Read-heavy workloads, archive queries, and transaction broadcasting each hit infrastructure tuned for that specific pattern. This approach delivers consistent performance under variable load rather than degrading as traffic spikes.
For teams with the most demanding reliability requirements, Quicknode's Dedicated Clusters provide fully isolated, private node infrastructure. Each cluster runs redundant nodes within a region, with independent distribution paths, so no shared traffic from other customers can impact your performance. Dedicated Clusters come with guaranteed uptime SLAs, Prometheus Exporter support for custom monitoring, and 14-day log retention for full operational visibility. This level of infrastructure is what powers some of the largest wallets, exchanges, and DeFi protocols in Web3.
Frequently Asked Questions
What is node reliability in blockchain?
Node reliability is how consistently and accurately a blockchain node answers requests without downtime, errors, or stale data. A reliable node stays synced to the chain tip, responds quickly, and remains available so your application can read and write blockchain data without interruption.
What is a good uptime SLA for a blockchain node?
Production applications should target 99.9% uptime or higher, which allows for under roughly 9 hours of downtime per year. Demanding workloads such as exchanges and DeFi protocols often require a 99.99% SLA, leaving under an hour of downtime annually.
How do you monitor node reliability?
Continuously track block height delta, error rate, response latency, and peer count, then alert when any of them crosses a threshold. Pairing these metrics with logs and traces shows not just that a node is degrading but why, so you can fail over or fix it before users notice.
What is the difference between node reliability and node performance?
Performance is about speed, meaning how fast a node responds. Reliability is about consistency, meaning whether the node responds correctly and stays available over time. A node can be fast but unreliable if it crashes often, and reliable but slow if it is underpowered. Production infrastructure needs both.
Does using multiple nodes improve reliability?
Yes. Running redundant nodes with automatic failover removes single points of failure, so one node crashing does not take your application offline. This redundancy is the foundation of high availability in blockchain infrastructure.