Answers>Learn about blockchain basics>Onchain vs Offchain data: what’s the difference?
Onchain vs Offchain data: what’s the difference?
// Tags
on-chain vs off-chainblockchain data storage
TL;DR: Onchain data lives directly on the blockchain, making it permanent, transparent, and verifiable by anyone. Offchain data is stored outside the blockchain, typically on traditional servers, decentralized storage networks like IPFS, or private databases. Most real-world applications use a combination of both, keeping critical state onchain while storing larger or less essential data offchain to save cost and improve performance.
The Simple Explanation
Every blockchain has limited space. Storing data onchain means writing it into a transaction or smart contract state that gets permanently recorded across every node in the network. This makes the data tamper-proof and universally accessible, but it comes at a cost. On Ethereum, storing just 32 bytes of data can cost several dollars depending on gas prices. Storing an entire image or document onchain would be prohibitively expensive.
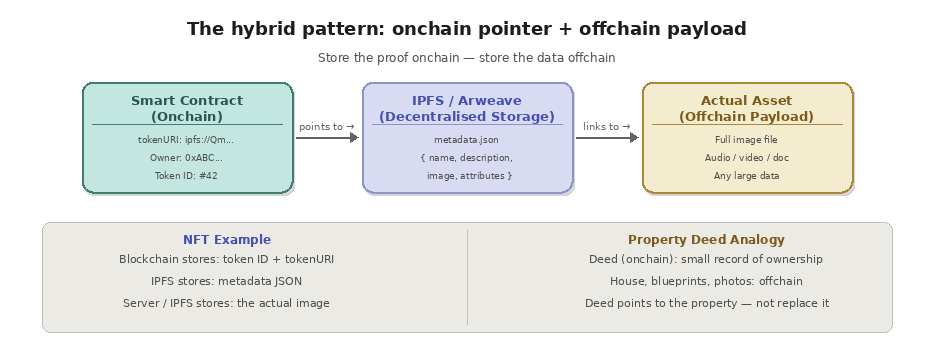
That is where offchain data comes in. Instead of storing a full image on the blockchain, a developer might store the image on IPFS (a decentralized file storage network) and then store only the IPFS content hash onchain. The blockchain record proves what the data should be, and the offchain storage actually holds it. This hybrid approach gives you the verifiability of blockchain with the scalability of traditional or decentralized storage systems.
Think of it like a property deed. The deed itself (a small, critical record of ownership) gets recorded in the county clerk's office. But the actual house, the blueprints, the inspection reports, and the photos all exist elsewhere. The deed points to the property. The blockchain works the same way: it stores the critical proofs and pointers while larger datasets live offchain.
What Counts as Onchain Data
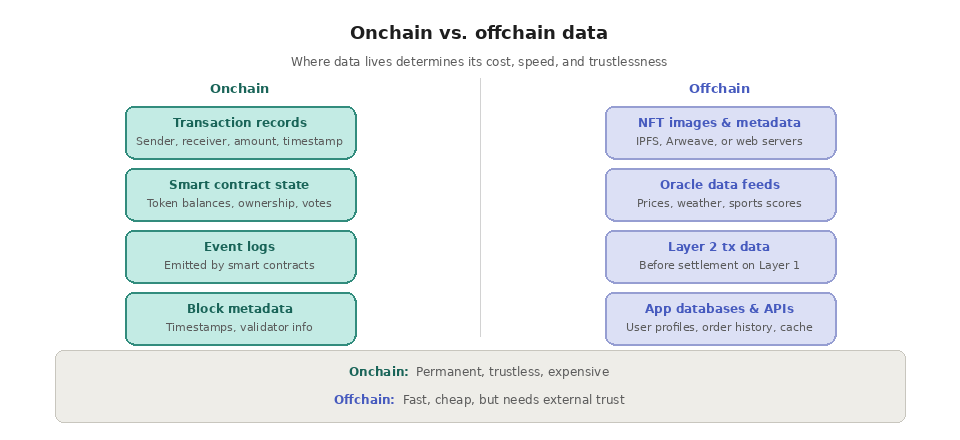
Onchain data includes everything that is permanently recorded in the blockchain's state or transaction history. This covers transaction records (sender, receiver, amount, timestamp), smart contract code and state variables (token balances, ownership records, governance votes), event logs emitted by smart contracts, and block metadata like timestamps and validator information.
When a user swaps tokens on a decentralized exchange, the entire transaction, including the amounts, the addresses involved, and the resulting state changes, is recorded onchain. When an NFT is minted, the token ID, the owner's address, and the metadata URI are all stored in the smart contract's onchain state. This data is immutable once confirmed, meaning no one can retroactively change it.
Onchain data is what gives blockchain its core value proposition: trustless verification. Anyone running a node or querying an RPC endpoint can independently verify any piece of onchain data without relying on a third party. It is the single source of truth for the network.
What Counts as Offchain Data
Offchain data is anything that exists outside the blockchain but is referenced by or relevant to onchain activity. This includes NFT images and metadata files stored on IPFS or centralized servers, large datasets used by dapps (user profiles, order histories, analytics), oracle data feeds that bring real-world information (prices, weather, sports scores) onto the blockchain, Layer 2 transaction data before it is batched and settled on Layer 1, and application front-ends and APIs that interact with smart contracts.
The most common pattern is storing a content hash or URI onchain that points to offchain data. For example, most NFT smart contracts store a tokenURI that points to a JSON metadata file hosted on IPFS or a web server. That JSON file contains the image URL, description, and attributes. The blockchain knows the pointer. The offchain system holds the payload.
Oracles like Chainlink are a critical bridge between onchain and offchain worlds. Smart contracts cannot natively access external data. They cannot check a stock price, verify a weather event, or confirm a real-world shipment. Oracles fetch this offchain data and deliver it onchain in a verifiable way, enabling smart contracts to react to real-world events.
The Tradeoffs
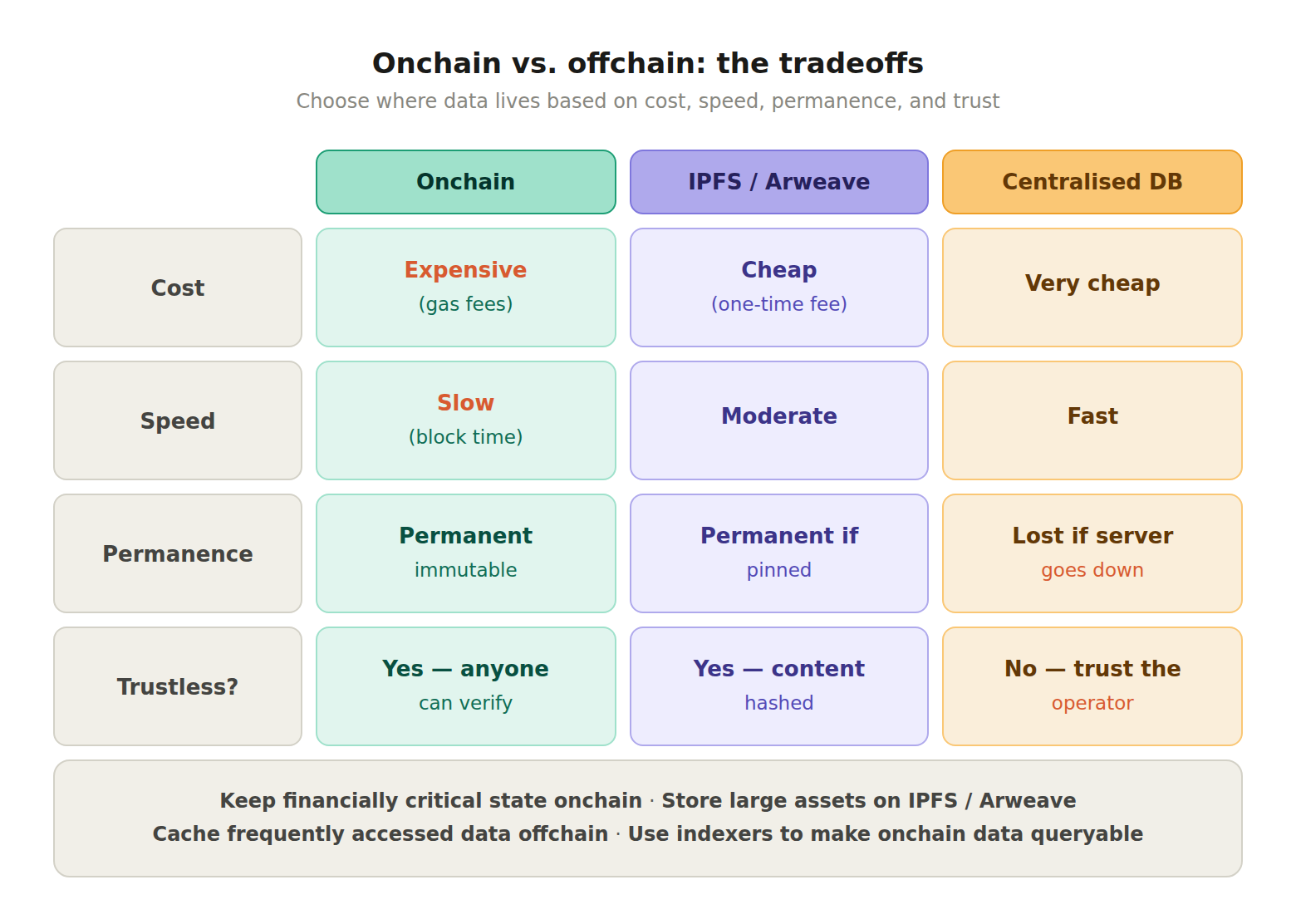
The decision of what to store onchain versus offchain comes down to cost, speed, permanence, and trust requirements. Onchain storage is expensive but permanent and trustless. Offchain storage is cheap and fast but introduces dependencies on external systems. If an NFT's image is stored on a centralized server and that server goes down, the NFT still exists onchain but the art it represents becomes inaccessible. If the image is on IPFS and no one is pinning it, the same thing can happen.
Decentralized storage protocols like IPFS and Arweave aim to solve this by distributing files across a network of nodes rather than relying on a single server. IPFS uses content-addressed storage, meaning files are referenced by their cryptographic hash rather than a server location. As long as at least one node on the network pins the file, it remains accessible. Arweave takes this further by incentivizing permanent storage through a one-time fee model.
For developers building production applications, the architecture typically involves keeping all financially critical state onchain (balances, ownership, approvals), storing larger assets on decentralized storage like IPFS, caching frequently accessed data in offchain databases for performance, and using indexers and data pipelines to make onchain data queryable.
What is the difference between onchain and offchain data?
Onchain and offchain data differ in where they live and what guarantees they carry. Onchain data is written into the ledger of a blockchain and validated by every node, while offchain data sits in external systems that the chain only references. The table below compares them across the attributes that matter most.
Attribute
Onchain data
Offchain data
Location
Stored in blocks and contract state
Servers, IPFS, or databases
Cost
High, paid in gas per byte
Low, standard storage pricing
Speed
Limited by block times
Fast, near instant reads and writes
Permanence
Immutable once confirmed
Mutable unless pinned or archived
Transparency
Public and verifiable by anyone
Private or access controlled
Trust model
Trustless, secured by consensus
Depends on the host or storage network
Best for
Balances, ownership, proofs
Images, large files, cached analytics
When should you store data onchain versus offchain?
The rule of thumb is simple: keep anything that must be trustless, final, and publicly verifiable onchain, and push everything else offchain to save cost and gain speed. The table below maps common data types to the storage layer that usually fits best.
Data type
Recommended location
Why
Token balances and ownership
Onchain
Must be trustless and final
Smart contract logic
Onchain
Execution must be verifiable
NFT media and metadata
Offchain (IPFS)
Too large and costly to store onchain
Analytics and search indexes
Offchain
Needs fast queries, rebuilt from chain data
Real-world data feeds
Offchain via oracles
Chains cannot fetch external data
The logic that enforces these rules lives in smart contracts, and the offchain side usually depends on blockchain indexing to turn raw onchain events into fast, searchable records. If you are deciding how to read state at scale, see how teams approach querying blockchain data.
Are Layer 2 and rollup transactions onchain or offchain?
Layer 2 transactions start offchain and become onchain once they settle. A Layer 2 blockchain executes transactions on a separate layer for speed, then a rollup batches many of them and posts compressed data plus a proof back to Layer 1. So execution happens offchain, but the final data and security anchor onchain. The two main designs, optimistic and ZK rollups, differ in how they prove that the batched offchain work is valid.
How do oracles connect offchain data to the blockchain?
Smart contracts cannot reach the internet on their own, so they rely on oracles to bring offchain information onchain. An oracle network fetches external data such as asset prices or event outcomes, reaches agreement on the value, and writes it into a contract that other contracts can read. This is how a DeFi protocol can react to a market price or an insurance contract can respond to a real-world event, all while keeping the final, acted-upon value onchain and verifiable.
Frequently Asked Questions
Is offchain data secure?
It can be, but the guarantees are different. Offchain data inherits the security of wherever it is stored, so a centralized server is a single point of failure, while content-addressed networks like IPFS or Arweave spread copies across many nodes. Storing a cryptographic hash of the offchain data onchain lets anyone verify that the offchain payload has not been tampered with.
What happens to an NFT if its offchain image goes offline?
The token itself still exists onchain, but the artwork it points to can become unreachable if the host disappears and no one pins the file. This is why serious projects store NFT media on IPFS or Arweave and keep the content hash onchain rather than a fragile web URL.
Can smart contracts read offchain data directly?
No. Smart contracts are deterministic and isolated from the outside world, so they cannot make network calls. They depend on oracles to deliver offchain data onchain in a verifiable form before they can use it.
Is IPFS onchain or offchain?
IPFS is offchain. It is a decentralized storage network that holds files outside the blockchain, while the blockchain typically stores only the IPFS content hash that points to those files.
How do you access historical onchain data?
Recent state is easy to read from any node, but full history often requires archive nodes or a backfill pipeline. See accessing historical blockchain data for the common approaches and their tradeoffs.
How Quicknode Fits In
Working with both onchain and offchain data requires reliable infrastructure. Quicknode's Core API gives you low-latency RPC access to 80+ chains for reading and writing onchain data. Quicknode Streams lets you capture real-time blockchain events and route them to offchain destinations like webhooks, PostgreSQL databases, or S3 buckets, making it easy to build data pipelines that bridge the onchain and offchain worlds. For decentralized storage, Quicknode's IPFS pinning service and dedicated gateways let you store and retrieve offchain content without managing your own IPFS nodes.