Answers>Learn about blockchain data streaming>Real-time vs historical blockchain data
Real-time vs historical blockchain data
// Tags
real-time blockchain datahistorical blockchain data
TL;DR: Real-time blockchain data is information from the chain tip, the most recently produced blocks and the transactions happening right now. Historical blockchain data is everything that came before, from the genesis block to the recent past. Applications need both: real-time data powers live dashboards, transaction monitoring, and instant notifications, while historical data supports analytics, auditing, backfilling databases, and training models. The infrastructure challenge is that accessing each type efficiently requires different tools, and the best architectures unify both into a single pipeline.
The Simple Explanation
Think of a blockchain as a continuously growing ledger. At any given moment, the newest entry is being written at the tip. Everything behind it is history. The distinction between real-time and historical data is not about the data itself (blocks are blocks, transactions are transactions) but about when and how your application needs to access it.
Real-time data is what is happening now. A new block was just produced. A token transfer just landed. A smart contract event just fired. Your application needs to know about these events as quickly as possible, ideally within seconds of the block being finalized. Real-time data access is latency-sensitive. The value of the information degrades with every second of delay. A trading bot that learns about a price change 30 seconds after it happens is at a severe disadvantage compared to one that learns about it in 2 seconds.
Historical data is what already happened. A user wants to see their complete transaction history from the last year. An analytics platform needs to calculate the total volume traded on a DEX since launch. A compliance team needs to trace fund flows across six months of activity. Historical data access is throughput-sensitive. The challenge is not how fast you get a single record but how efficiently you can retrieve, process, and store millions or billions of records spanning thousands or millions of blocks.
Different Access Patterns
The access patterns for real-time and historical data are fundamentally different, which is why they typically require different infrastructure approaches.
Real-time data access follows a subscription pattern. Your application says "notify me whenever a new block is produced" or "tell me whenever this contract emits a Transfer event." The data arrives as a continuous stream, one block at a time, in the order the chain produces them. Your application processes each block as it arrives and updates its state accordingly. The key requirements are low latency (minimal delay between block production and delivery), reliability (never miss a block), and ordering (blocks arrive in the correct sequence with no gaps).
Historical data access follows a batch processing pattern. Your application says "give me all blocks from number 10,000,000 to 20,000,000" or "retrieve every ERC-20 transfer event from the USDC contract since deployment." The data arrives in bulk, potentially millions of records, and your application processes it in large batches before loading it into a database or data warehouse. The key requirements are throughput (process as many blocks per second as possible), completeness (no missing blocks or gaps), and cost efficiency (minimize the compute and bandwidth required to retrieve terabytes of data).
These different requirements explain why a single approach rarely serves both needs well. WebSocket subscriptions work for real-time data but cannot retrieve historical blocks. Sequential RPC polling can technically fetch historical data but is painfully slow and expensive at scale. Purpose-built data pipelines that handle both real-time streaming and historical backfilling through the same interface solve the architectural mismatch.
Why Applications Need Both
Almost every production blockchain application requires both real-time and historical data, often simultaneously. A DeFi dashboard needs historical data to display charts showing a token's price over the last 90 days, a pool's TVL trend over the last year, and a user's complete position history. It simultaneously needs real-time data to update the current price, show live trades as they happen, and alert the user when their position approaches a liquidation threshold. If the dashboard only had real-time data, it would start with a blank screen every time it loaded. If it only had historical data, the numbers would always be stale.
A blockchain indexer needs historical data to build its initial database by processing every block from genesis (or from the contract's deployment block) to the present. Once the backfill is complete, it needs real-time data to keep the database current by processing each new block as it is produced. The transition from historical backfill to real-time streaming must be seamless, with no gap between the last historical block processed and the first real-time block received. Any gap means missing data. Any overlap means duplicate data.
An NFT marketplace needs historical data to display ownership history, past sale prices, and provenance for every token. It needs real-time data to show new listings the moment they are created, update prices when auctions receive bids, and confirm transfers when sales complete. Traders rely on historical data for valuation and real-time data for execution.
A compliance monitoring system needs historical data to conduct retroactive investigations when suspicious activity is flagged. It needs real-time data to detect suspicious patterns as they happen and generate alerts within minutes rather than days. The system must be able to pivot between modes, streaming new activity in real time while simultaneously querying months of historical records for context.
The Architecture Challenge
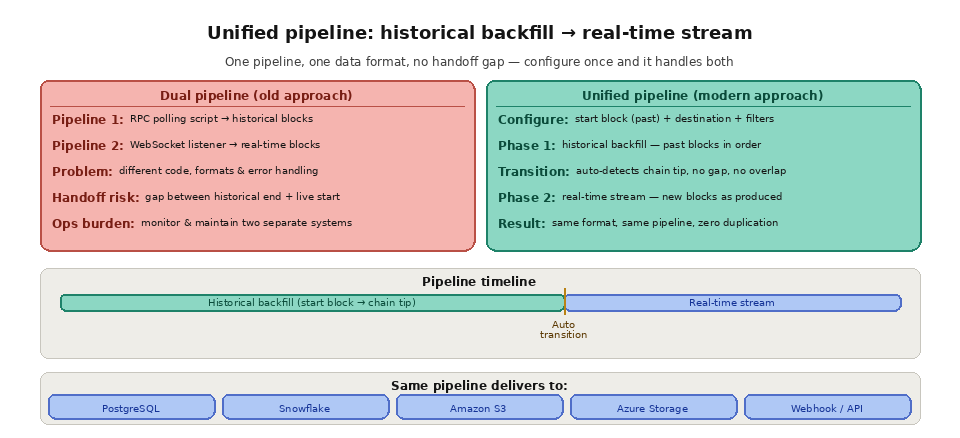
The traditional approach to handling both data types involves building two separate systems: a historical backfill pipeline (usually a script that iterates through blocks via RPC) and a real-time listener (usually a WebSocket subscription or polling loop). This dual-pipeline architecture creates several problems. The two systems use different code, different error handling, different data formats, and different delivery mechanisms. Keeping them in sync during the handoff from historical to real-time is error-prone. Maintaining and monitoring two separate pipelines doubles the operational burden.
A unified data pipeline that handles both historical and real-time data through a single interface eliminates these problems. You configure one pipeline with a starting block (in the past for historical, or "latest" for real-time only), and the system delivers data from that starting point forward, transitioning seamlessly from historical backfill to real-time streaming once it catches up to the chain tip. Same data format, same delivery mechanism, same error handling, same monitoring. The pipeline does not care whether the block it is processing was produced three years ago or three seconds ago.
What is the difference between real-time and historical blockchain data?
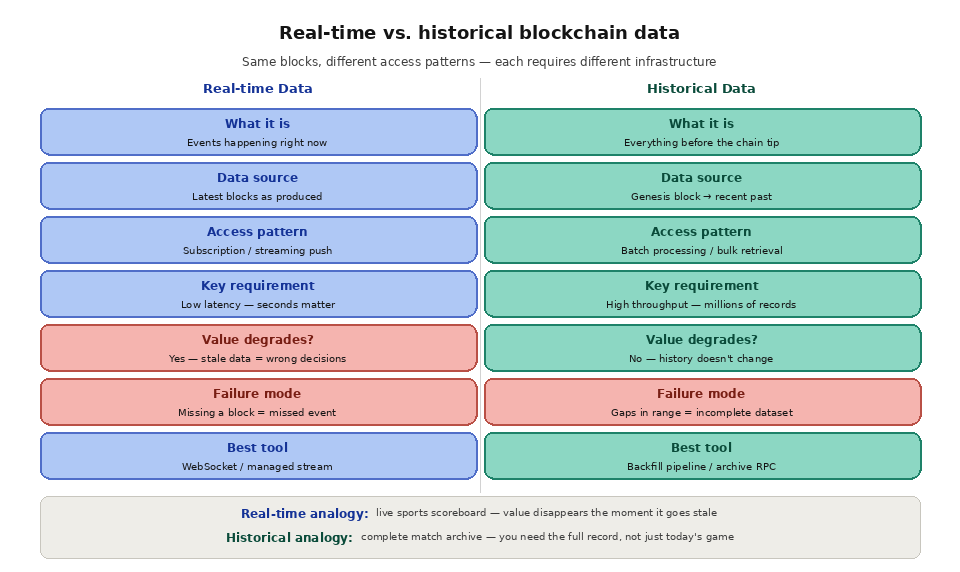
The data is the same blocks and transactions; what differs is when you need it and how you fetch it. Real-time data is read at the chain tip through a subscription, so it is optimized for low latency. Historical data is read in bulk from past blocks, so it is optimized for throughput and cost. This is why querying blockchain data efficiently usually means choosing a different tool for each job. The table below summarizes the contrast.
Dimension
Real-time data
Historical data
Definition
The chain tip and transactions happening now
Everything from genesis to the recent past
Access pattern
Subscription, one block at a time
Batch, many blocks at once
Sensitive to
Latency
Throughput and cost
Typical tool
Streams or WebSocket subscriptions
Backfills, archive nodes, indexers
Powers
Live dashboards, alerts, monitoring
Analytics, audits, model training
Freshness
Seconds old
Minutes to years old
How do you access historical blockchain data?
There are three common ways to read the past. You can query an archive node, which retains full state at every block height and answers point lookups for any historical moment. You can run a backfill, which iterates over a block range and exports the results in bulk. Or you can use an indexer that has already processed and stored the data in a queryable database. Each trades off setup effort, speed, and cost differently, and the right pick depends on how much history you need and how often. For a deeper look at the options and their tradeoffs, see accessing historical blockchain data.
Which applications need real-time versus historical data?
Most production applications need both, but the balance shifts by use case. Latency-sensitive features lean real-time, while analytical and audit features lean historical. The table below maps common workloads to their primary data need, and you can find more patterns in these blockchain streaming use cases.
Use case
Primary data need
Why
Trading bot
Real-time
Acts on price changes within seconds
Tax or audit report
Historical
Reconstructs a full activity record
Blockchain indexer
Both
Backfills history, then streams new blocks
Liquidation alerts
Real-time
Must fire before a position is liquidated
DEX volume analytics
Historical
Aggregates millions of past trades
NFT provenance
Both
Shows ownership history plus live listings
How do you unify real-time and historical data in one pipeline?
The cleanest architecture configures a single pipeline with a starting block in the past, processes forward in order, and then transitions automatically to live delivery once it reaches the chain tip. That removes the fragile handoff between a backfill script and a separate live listener. If you are weighing how data should arrive, the choice between polling and streaming largely determines how hard that handoff is to build yourself, and a managed service like Quicknode Streams handles ordering, gaps, and reorgs for you.
Frequently Asked Questions
Is real-time data more valuable than historical data?
Neither is universally more valuable; they serve different jobs. Real-time data drives features where freshness is everything, like alerts and trade execution, while historical data drives analytics, audits, and any view that needs context from the past. Most serious applications depend on both at once.
How far back can I query historical blockchain data?
With the right infrastructure you can read all the way back to the genesis block. Full state at arbitrary historical heights requires an archive node rather than a pruned full node, which is why the distinction between a full node and an archive node matters when you plan historical access.
Can one pipeline serve both real-time and historical data?
Yes. A unified streaming pipeline can start from a past block, backfill forward, and then continue into live data without a gap or a second system. This is the core idea behind blockchain data streaming, which delivers ordered data whether the block is old or brand new.
What is the fastest way to backfill historical data?
Sequential RPC scripts are simple but slow and expensive at scale. Purpose-built backfill tooling that exports block ranges in bulk to a database or data warehouse is typically far faster and cheaper, because it is optimized for throughput rather than one request at a time.
Do I need an indexer for historical queries?
Not always. For occasional lookups, an archive node or a backfill is enough. But if you run frequent, complex queries over large ranges, blockchain indexing pre-processes the data into a queryable store so each query is fast instead of recomputed from raw blocks.
How Quicknode Handles Both
Quicknode Streams provides a unified pipeline for both real-time and historical blockchain data. A single Stream can be configured to start from any historical block and process forward, delivering data in finality order to your destination (PostgreSQL, Snowflake, Amazon S3, Azure Storage, webhooks, and more). Once the Stream reaches the chain tip, it automatically transitions to real-time mode and continues delivering new blocks as they are produced. There is no gap, no handoff logic, and no second pipeline to maintain.
For real-time point queries, Quicknode's Core API provides globally distributed RPC access with archive support on all plans, meaning your application can query the current state of the chain or any historical state at any block height through a single endpoint. Enhanced API methods aggregate common multi-step queries into single calls, reducing latency for real-time reads. For historical backfills specifically, Quicknode offers one-click backfill templates with pre-configured datasets across 20+ chains, transparent cost and time estimates, and delivery speeds up to 7x faster than RPC-based scripts.