Answers>Learn about blockchain data streaming>Polling vs streaming blockchain data
Polling vs streaming blockchain data
// Tags
polling vs streaming websocket blockchain
TL;DR: Polling is a pull-based pattern where your application repeatedly asks a blockchain node for new data at fixed intervals. Streaming is a push-based pattern where new data is delivered to your application automatically as it is produced onchain. Polling is simple to implement but wastes resources, introduces latency, and risks missing data. Streaming is more efficient, faster, and more reliable at scale, but requires different infrastructure. For most production blockchain applications, streaming is the superior approach for data ingestion.
The Simple Explanation
Every blockchain application needs to know when something happens onchain. A wallet needs to know when its user receives a transfer. A DeFi protocol needs to detect when a price oracle updates. A trading bot needs to see new transactions the moment they enter a block. An analytics platform needs to process every block as it is produced. The question is how your application finds out about these events.
With polling, your application runs a loop: call the RPC endpoint, check if anything new has happened, process any new data, wait a fixed interval, repeat. This is the pattern most developers learn first because it maps naturally to how HTTP APIs work. Set up a timer, make a request every N seconds, handle the response. It requires no special infrastructure beyond the ability to make HTTP requests.
With streaming, your application opens a connection or configures a data pipeline once, and new data arrives automatically. There is no loop, no timer, no repeated requests. When a new block is produced, the data flows to your application without your application asking for it. The application's job is simply to process incoming data as it arrives.
How Polling Works in Practice
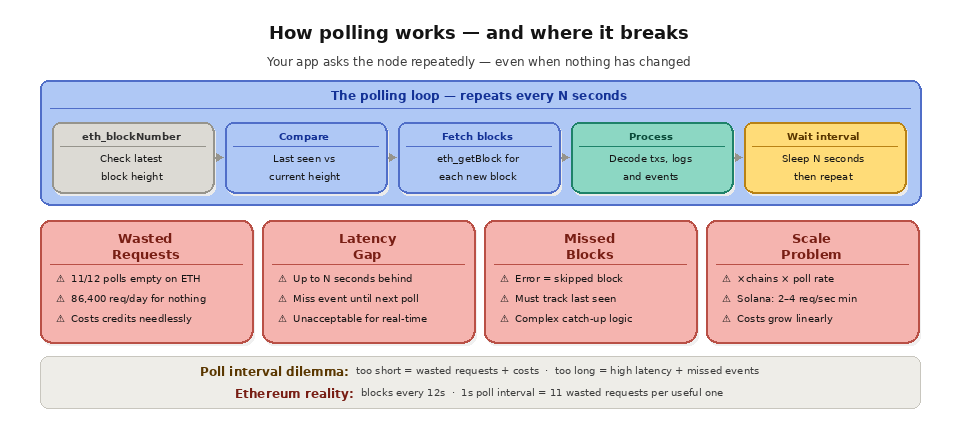
A typical polling implementation for monitoring new blocks looks like this: your application calls "eth_blockNumber" to get the latest block, compares it to the last block it processed, fetches any new blocks via "eth_getBlockByNumber," extracts the data it needs, and schedules the next poll. Each iteration requires at minimum one RPC call (to check the latest block number) and potentially many more (to fetch full block data, transaction receipts, and event logs for each new block).
The polling interval is a critical design decision. Poll too frequently and you waste RPC requests (and credits) asking "anything new?" when the answer is "no." On Ethereum, where blocks are produced every 12 seconds, polling every second means 11 out of 12 requests return nothing useful. Poll too infrequently and you introduce latency. If your interval is 30 seconds, you might not discover a new block until 30 seconds after it was produced. You might also process multiple blocks per interval, creating uneven load on your system.
Polling introduces several reliability risks. If a poll fails due to a network error, rate limit, or node issue, your application might miss a block entirely unless it tracks the last processed block number and backtracks on the next successful poll. If your application crashes or restarts, it must determine where it left off and resume from that point, handling any blocks produced during downtime. If the polling worker falls behind due to processing delays, the gap between the chain tip and your application's state grows, and catching up requires processing a backlog of blocks.
On high-throughput chains, polling becomes especially problematic. Solana produces slots every 400ms. Arbitrum and Base produce blocks every 250ms. Polling these chains at their block production rate requires 2-4 RPC requests per second just for block number checks, plus additional requests for full block data. At scale across multiple chains, the RPC request volume (and cost) grows linearly with the number of chains and the block production rate of each.
How Streaming Works in Practice
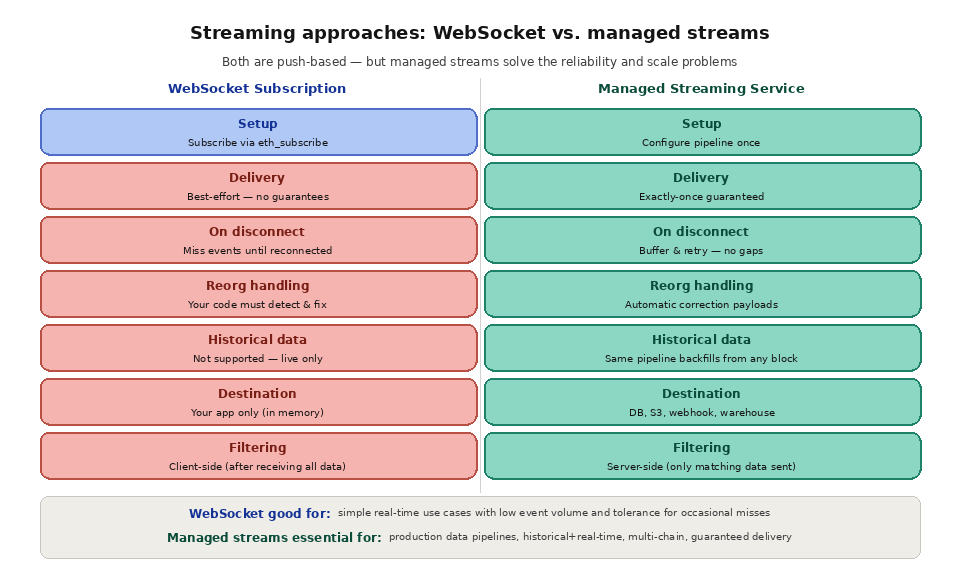
WebSocket subscriptions are the simplest form of blockchain streaming. Your application opens a persistent WebSocket connection to a node and sends a subscription request (like "eth_subscribe" with "newHeads"). The node pushes each new block header to your application over the open connection as soon as it is produced. No polling, no wasted requests, no latency gap.
WebSockets work well for simple use cases but have significant limitations at scale. Connections are stateful and can drop due to network issues, server restarts, or idle timeouts. When a connection drops, your application misses any events that occur before reconnection, and it must detect the disconnection, reconnect, and backfill the gap. Managing multiple concurrent WebSocket connections across multiple chains adds complexity. WebSocket subscriptions also do not support historical data. If you need to process blocks from last week, WebSockets cannot help.
Purpose-built streaming services address these limitations. Instead of maintaining fragile WebSocket connections, your application configures a data pipeline that the streaming service manages end-to-end. The service connects to blockchain nodes, processes each block, applies your filters, and delivers the results to your destination with guaranteed delivery. If your destination is temporarily unavailable, the service buffers data and retries. If a reorg occurs, the service sends correction payloads. If you need historical data, the same pipeline can backfill from any starting block.
Comparing the Two Approaches
Latency is the most visible difference. Polling always has latency equal to the polling interval in the best case, and longer in practice due to processing time and error recovery. Streaming delivers data as soon as it is available, typically within seconds of a block being produced. For latency-sensitive applications like trading bots or real-time dashboards, streaming is meaningfully faster.
Resource efficiency is the second major difference. Polling generates request volume proportional to the polling frequency, regardless of whether new data exists. A polling worker checking for new blocks every second makes 86,400 requests per day even if it is only interested in one specific event that fires once a week. Streaming consumes resources proportional to the actual data volume. If nothing happens that matches your filter criteria, nothing is delivered, and no resources are consumed on your end.
Reliability separates the two approaches at scale. Polling requires your application to maintain its own state tracking, gap detection, error recovery, and catch-up logic. Every edge case (missed blocks, duplicate processing, reorgs, rate limits, node failovers) must be handled in your code. Streaming services handle these edge cases on the provider side, delivering a gapless, ordered, deduplicated feed that your application can process without worrying about infrastructure reliability.
Complexity is the tradeoff. Polling is simpler to implement initially. A basic polling loop can be written in 20 lines of code. But that simplicity is deceptive, because production-hardened polling requires error handling, backoff logic, state management, reorg detection, and monitoring that can balloon to hundreds of lines. Streaming requires upfront configuration of a data pipeline and a destination system that can receive pushed data (like a webhook server or a database with appropriate ingestion logic), but once configured, it requires far less ongoing maintenance.
What is the difference between polling and streaming?
Polling and streaming solve the same problem, getting fresh onchain data into your application, but they invert the control flow. With polling your code is the active party: it repeatedly calls an RPC endpoint and asks whether anything changed. With streaming the provider is the active party, pushing each new block or matching event to you the moment it is produced. The table below compares the two patterns across the dimensions that matter most in production.
Dimension
Polling
Streaming
Data flow
Pull-based, your app requests data
Push-based, data is delivered automatically
Latency
Equal to the poll interval or longer
Within seconds of block production
Resource usage
Proportional to poll frequency, even when idle
Proportional to actual data volume
Reliability at scale
Your app handles gaps, retries, and reorgs
Provider delivers an ordered, deduplicated feed
Historical data
Supported by re-querying past blocks
Supported by backfilling the same pipeline
Setup complexity
Trivial to start, costly to harden
Configure once, low ongoing maintenance
Best for
Simple scripts and low-frequency checks
Real-time apps and high-throughput chains
How do you choose a polling interval?
If you do poll, the interval should track the block time of the chain you are reading. Polling much faster than blocks are produced wastes requests and can trigger rate limiting, while polling much slower than the block time adds avoidable latency and forces your worker to process several blocks at once. The table below lists typical block times and the practical polling implication for each network.
Blockchain
Approximate block time
Polling implication
Bitcoin
About 10 minutes
A 1 to 2 minute interval is more than enough
Ethereum
About 12 seconds
Poll every 4 to 12 seconds to stay current without waste
BNB Smart Chain
About 3 seconds
Sub-block polling adds load with little benefit
Base
About 250 ms
Polling cannot keep up cleanly; prefer streaming
Solana
About 400 ms
High request volume; streaming is strongly preferred
When should you still use polling?
Streaming is the better default for most production workloads, but polling remains a reasonable choice in a few cases. One-off scripts, backfills, and infrequent batch jobs rarely justify a managed pipeline. Polling is also fine when you only need a single value on demand, such as a balance check before a user action, where there is no continuous feed to subscribe to. When freshness and volume do matter, though, the tradeoffs shift quickly, so it helps to understand the difference between real-time and historical data before committing to an approach.
How does streaming handle reorgs and dropped data?
The hardest part of consuming live blockchain data is not the happy path, it is the edge cases. A chain reorganization can replace a block your application already processed, and a dropped connection can leave a gap in your data. With raw polling or WebSockets you must detect and repair these situations yourself. A managed service such as Quicknode Streams handles them for you: it delivers data in finality order, emits correction payloads when a reorg occurs, and buffers and retries when your destination is unavailable. That difference is what makes push-based delivery so much easier to operate at scale.
Frequently Asked Questions
Is streaming always better than polling?
Not always. For most production applications that need continuous, low-latency data, streaming wins on efficiency and reliability. But for one-off scripts, simple balance checks, or low-frequency jobs, polling is perfectly adequate and easier to set up. The right choice depends on how fresh your data must be and how much volume you process. For a primer on the push-based model, see what blockchain data streaming is.
How often should I poll an RPC endpoint?
Match your polling interval to the chain's block time. On Ethereum, polling every 4 to 12 seconds keeps you current without wasting calls. On fast chains like Solana or Base, polling at the block rate is impractical and streaming is the better fit. Polling far faster than blocks are produced mostly returns no new data and burns request budget. See how RPC requests work for what each call involves.
Does polling cost more than streaming?
It often does at scale. Polling generates requests on a fixed schedule whether or not new data exists, so a busy polling worker can make tens of thousands of calls per day to capture a handful of events. Streaming consumes resources in proportion to the data that actually matches your filters, which usually means fewer wasted requests and lower cost for continuous workloads.
What happens to my data during a reorg?
With naive polling or raw WebSockets, a reorg can leave your application holding transactions that no longer exist on the canonical chain. A managed streaming service detects the reorg and sends correction payloads so your state stays consistent. Understanding throughput vs latency also helps you decide how long to wait before treating data as settled.
Can I get historical data from a streaming service?
Yes. Unlike WebSocket subscriptions, which only deliver new events from the moment you connect, a full streaming pipeline can backfill from any past block using the same configuration. This lets you replay history and then transition seamlessly into live data without running two separate systems.
How Quicknode Supports Both Patterns
Quicknode's Core API supports both polling via HTTP RPC endpoints and real-time subscriptions via WebSocket connections across all supported chains. For applications that use polling, Quicknode's guide to efficient RPC requests covers best practices for minimizing wasted calls, implementing proper error handling, and managing rate limits.
For applications ready to move beyond polling, Quicknode Streams provides a fully managed streaming pipeline. Streams delivers real-time blockchain data with guaranteed delivery, finality-order processing, automatic reorg handling, and server-side filtering, all without requiring your application to maintain WebSocket connections or polling infrastructure. Streams supports delivery to webhooks, PostgreSQL, Snowflake, Amazon S3, Azure Storage, and more, making it adaptable to any backend architecture. A direct comparison guide between WebSocket subscriptions and Streams is available in Quicknode's documentation, covering the tradeoffs and migration path for teams transitioning from polling or WebSocket-based architectures.