Answers>Learn about blockchain data streaming>What is blockchain data streaming?
What is blockchain data streaming?
// Tags
blockchain data streamingreal-time blockchain data
TL;DR: Blockchain data streaming is a push-based approach to accessing blockchain data where new blocks, transactions, and events are delivered to your application or database automatically as they are produced onchain. Instead of your application repeatedly asking the node "anything new yet?" (polling), a streaming service sends data to you the moment it is available. Streaming reduces latency, eliminates missed events, simplifies your backend architecture, and scales far more efficiently than traditional request-response patterns.
The Simple Explanation
There are two fundamental ways to get data from any system: you can ask for it (pull), or it can be sent to you (push). For most of blockchain's history, developers have used the pull model. Your application sends an RPC request to a node, the node sends back a response, and your application decides when to ask again. This is the polling pattern. It is simple to implement but inefficient, especially when your application needs to stay in sync with the blockchain's latest state.
Streaming flips this model. Instead of your application asking "what happened in the latest block?" thousands of times per day, you establish a data pipeline once and the streaming service delivers every new block's data to your application or database as it is produced. Your application becomes a consumer of a continuous data feed rather than a requester of discrete data snapshots.
The analogy is the difference between refreshing a news website every five minutes versus subscribing to a push notification that alerts you the moment a story breaks. Both get you the same information eventually, but the push model is faster, less wasteful, and more reliable.
How Blockchain Data Streaming Works
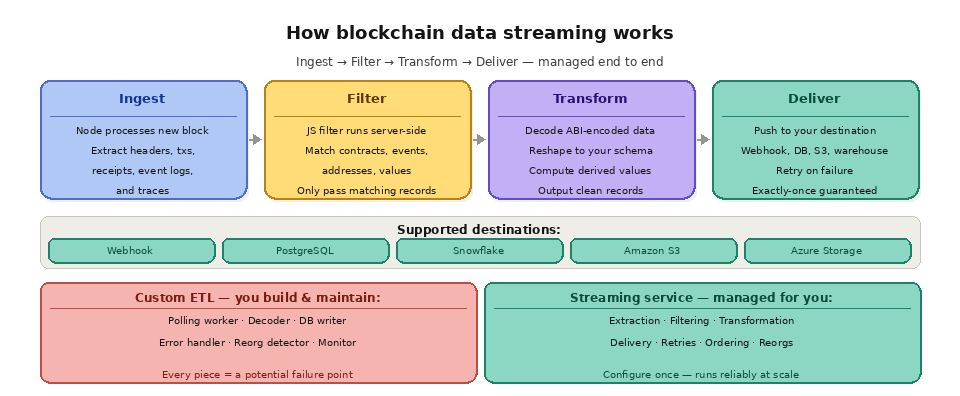
A streaming service sits between blockchain nodes and your application or data infrastructure. On the ingestion side, the service connects to nodes across supported networks and processes each new block as it is finalized. It extracts the raw block data, including headers, transactions, transaction receipts (with event logs), and optionally execution traces. This raw data is the complete record of everything that happened in that block.
On the processing side, the streaming service applies any filters or transformations you have configured. Perhaps you only care about ERC-20 transfer events from a specific set of contracts. A filter written in JavaScript or another supported language runs against each block's data and passes through only the records that match your criteria. This server-side filtering is critical for efficiency because it means your destination only receives and stores the data you actually need, not the entire block.
On the delivery side, the filtered data is sent to your configured destination. This could be a webhook URL that your application listens on, a PostgreSQL database, a Snowflake data warehouse, an Amazon S3 bucket, Azure Blob Storage, or another supported endpoint. The streaming service handles delivery guarantees, including retries on failure, deduplication, and correct ordering, so your destination receives a gapless, sequential feed of blockchain data.
Streaming vs Traditional ETL Approaches
Traditional blockchain ETL (Extract, Transform, Load) pipelines require developers to build and maintain significant infrastructure. A typical custom ETL setup involves a polling worker that calls RPC endpoints on a schedule to fetch new blocks, a processing layer that decodes and transforms the raw data, a database writer that inserts records, an error handler that manages retries and failures, a reorg detector that identifies and rolls back data from abandoned forks, and monitoring to alert when any of these components break. Each piece adds complexity, and each is a potential point of failure.
Streaming services consolidate all of this into a single managed pipeline. The extraction, filtering, transformation, delivery, retry logic, ordering, and reorg handling all happen on the provider's infrastructure. Your responsibility is limited to configuring what data you want, where you want it sent, and how you want it shaped. This dramatically reduces the engineering effort required to build and maintain blockchain data infrastructure.
The performance difference is also substantial. A polling-based pipeline inherently has latency equal to the polling interval. If your worker checks for new blocks every 5 seconds, you could be up to 5 seconds behind the chain tip even when everything is working perfectly. Missed polls (due to errors, rate limits, or worker restarts) increase this gap. Streaming eliminates polling latency because data is pushed as soon as it is available. On high-throughput chains where blocks are produced every few hundred milliseconds, this difference is meaningful for latency-sensitive applications.
Key Features of Production Streaming
Several features distinguish production-grade streaming from a simple WebSocket subscription. Guaranteed delivery ensures that every block's data reaches your destination exactly once, even if the connection drops temporarily or your destination experiences a brief outage. The streaming service buffers and retries until delivery is confirmed, so you never have gaps in your data.
Finality-order delivery means data arrives in the order the blockchain considers canonical. On chains with variable finality times, the streaming service waits until a block is sufficiently confirmed before delivering it, preventing your application from processing data that might later be invalidated by a reorg. When reorgs do occur, the service detects the fork, identifies which blocks are no longer canonical, and sends correction payloads so your destination can update accordingly.
Historical backfilling allows you to use the same streaming pipeline for past data, not just new blocks. Instead of building a separate ETL process for historical data and a different one for real-time data, you configure a single stream with a starting block in the past and let it work forward through history, then seamlessly transition to real-time once it catches up to the chain tip. This unified pipeline simplifies your architecture and ensures consistency between historical and real-time data.
Server-side filtering and transformation reduce the volume of data that reaches your destination, lowering bandwidth costs, storage costs, and processing overhead. Filters can match on addresses, event signatures, function selectors, transaction values, or any other property of the block data. Transformations can reshape payloads, decode ABI-encoded data, compute derived values, and output records in a schema that matches your database tables.
How Quicknode Streams Delivers Blockchain Data Streaming
Quicknode Streams is a purpose-built blockchain data streaming and ETL service that delivers real-time and historical data across 80+ chains with built-in filtering, transformation, and guaranteed delivery. Streams supports multiple dataset types (blocks, transactions, receipts, event logs, traces) and multiple destinations (webhooks, PostgreSQL, Snowflake, Amazon S3, Azure Storage, and more).
Streams processes data in finality order with exactly-once delivery guarantees, automatically handles chain reorganizations by sending correction payloads, and supports configurable batching and compression for optimal throughput during historical backfills. JavaScript filters run on Quicknode's infrastructure, allowing you to decode events, match patterns, reference external key-value stores, and shape output payloads before data reaches your destination. One-click backfill templates provide pre-configured pipelines for common datasets across 20+ chains, with transparent cost and completion time estimates shown before you start.
For even more sophisticated workflows, Streams integrates with Quicknode Functions to enable serverless automation on top of streaming data. Functions can enrich records with additional onchain data, call external APIs, trigger notifications, or execute arbitrary business logic in response to streaming events. Together, Streams and Functions provide a complete blockchain data platform that replaces custom ETL infrastructure with a managed, scalable solution.
What is the difference between streaming and polling?
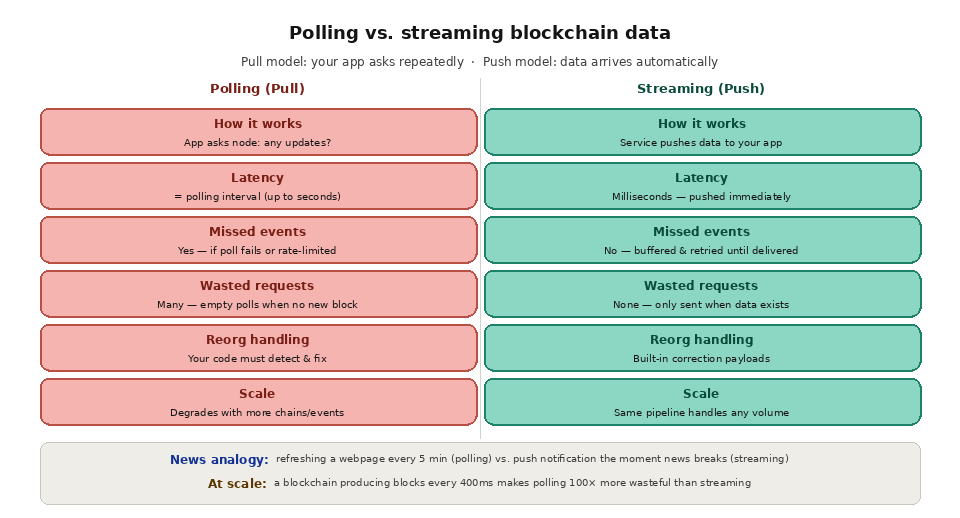
Polling and streaming are the two ways an application keeps up with onchain activity, and they sit at opposite ends of a spectrum. Polling is pull-based: your application repeatedly asks a node whether new data exists. Streaming is push-based: a service delivers new data to you the instant it is available. The table below compares them across the dimensions that matter most when you are choosing an approach.
Dimension
Polling
Streaming
Data flow
Application pulls on a schedule
Service pushes as data is produced
Latency
Bounded by the polling interval
Near real-time, no interval delay
Missed data risk
Gaps if a poll fails or is skipped
Guaranteed, gapless delivery
Reorg handling
You build it yourself
Built in via correction payloads
Operational load
You run and scale the workers
Managed by the provider
For a deeper comparison of the two delivery models and when each makes sense, see polling vs streaming.
What are common use cases for blockchain data streaming?
Streaming fits any workload that must react to onchain activity quickly or keep a database continuously in sync. Common examples include real-time wallet and portfolio tracking, DeFi dashboards, trading and liquidation bots, NFT mint and sale monitoring, fraud and compliance alerting, and analytics warehouses that ingest every block. Each of these benefits from low latency and gapless delivery rather than periodic snapshots. For a fuller catalog of patterns, see blockchain streaming use cases.
How does streaming handle real-time versus historical data?
A strong streaming pipeline treats real-time and historical data as one continuous timeline rather than two separate systems. You can start a stream from a block far in the past, let it backfill forward through history, and then transition seamlessly to live blocks once it catches up to the chain tip. This avoids maintaining two pipelines with two different code paths. To understand the trade-offs between fresh and archived data, see real-time vs historical blockchain data, and for backfill strategies see how to access historical blockchain data.
How does streaming deal with chain reorganizations?
Reorganizations are the hardest part of consuming live blockchain data, because a block your application already processed can be replaced by a competing block. Production streaming services handle this by delivering data in finality order and, when a reorg occurs, sending correction payloads that tell your destination which blocks are no longer canonical so it can roll back affected records. This removes one of the most error-prone pieces of custom pipelines. Learn more in what is a blockchain reorg.
How is streaming different from indexing?
Streaming and indexing solve related but distinct problems. Streaming is about delivery: getting onchain data to your destination as it happens. Indexing is about organization: structuring that data into a queryable database so you can run fast historical and aggregate queries. Many teams use streaming to feed an index, then query the index for analytics. See what is blockchain indexing and querying blockchain data for how the pieces fit together.
Frequently Asked Questions
Is blockchain data streaming the same as a WebSocket subscription?
Not quite. A WebSocket subscription is a low-level connection that pushes events while the socket stays open, but it offers no delivery guarantees and stops if the connection drops. Production streaming adds exactly-once delivery, finality ordering, reorg corrections, server-side filtering, and historical backfill on top of that basic push model.
Does streaming guarantee I will not miss any blocks?
Yes, with a production service. Guaranteed delivery means the provider buffers and retries until each block's data is confirmed at your destination, so you get a gapless feed even if your endpoint has a brief outage. Push-based event services like Quicknode Webhooks apply the same reliability principles to event notifications.
Can I filter streaming data before it reaches my destination?
Yes. Server-side filtering lets you match on addresses, event signatures, function selectors, values, or any other property of the block, so only the records you care about are delivered. This lowers bandwidth, storage, and processing costs because you never receive the data you do not need.
Can streaming replace a custom ETL pipeline?
For most teams, yes. A managed streaming service consolidates extraction, filtering, transformation, delivery, retries, ordering, and reorg handling into one pipeline, removing the many moving parts of a homegrown ETL stack. You configure what data you want and where it goes, and the provider operates the rest.
Which destinations can streaming data be delivered to?
Common destinations include webhook URLs, PostgreSQL, Snowflake, Amazon S3, and Azure Blob Storage, among others. This lets you wire streaming data directly into your application backend, your data warehouse, or your object storage without building custom connectors for each.